In this post, I will talk about the Antidetect Browser technology and the future of secure online management.
Online accounts are now part of daily life. Whether someone is managing ads, handling multiple projects, logging into services from different devices, or running automated workflows, they expect one thing: smooth account operation without unnecessary friction.
But the modern web doesn’t treat every login as “just another visit.” Websites often look at a combination of signals—device and browser behavior, technical configurations, network characteristics, and more—to decide whether an account action is legitimate or suspicious. When those signals don’t match, users can face problems such as verification loops, unexpected restrictions, or outright blocks.
This is where antidetect browser technology becomes relevant. In this article, we’ll explain what a digital fingerprint is, how web systems use fingerprint signals, why “one identity” can become “many identities” from a website’s perspective, and how antidetect browser approaches are designed to support secure, consistent online management.
Note: This article is educational and informational. It explains concepts around digital fingerprints and privacy-oriented browsing approaches at a high level.
1) What Is a Digital Fingerprint?
A digital fingerprint (in web terms) is a collection of browser- and device-related signals that help identify how a browser is operating. The key idea is simple:
Two different devices may look similar to a human.
But to software systems, they can behave differently in many small technical ways.
When those differences are combined, they become highly distinctive.
Unlike cookies (which you can often delete), fingerprints can still exist even after clearing cookies, because they can come from things the browser and device inherently provide.
Browser fingerprinting systems often rely on a mix of passive signals (data the browser reveals automatically) and active signals (data collected by running tests in the browser). Common examples of signals include browser and OS details, language and timezone, screen characteristics, installed fonts, and rendering behaviors such as Canvas or WebGL.
A simple analogy
Think of cookies like your name tag. If you remove the name tag, people may not know who you are. A fingerprint is more like your unique “handwriting style”—even if you remove the name tag, your style may still be detectable.
2) Why Websites Care About Fingerprints
If you’re wondering why websites try to identify devices and browsers, here are the practical reasons:
Fraud prevention Platforms want to detect suspicious login patterns, automated behaviors, and abuse.
Security and access control “New device” flows exist for user safety.
Anti-abuse scoring Many sites use risk scoring models. Fingerprint-like signals often feed into those models.
Operational stability Businesses want to reduce repeated bot traffic and repeated abuse attempts that overload systems.
Because fingerprints are often used as part of detection pipelines, any mismatch between what a website expects and what it observes can trigger friction.
3) How Fingerprints Are Built (In Plain Language)
Modern browser fingerprinting generally combines multiple signals. The most important thing to understand is that no single signal is always enough—the power comes from aggregation.
Here are common categories of fingerprint signals:
3.1 Passive signals (revealed automatically)
These might include:
Browser type and version
Operating system details
Language settings
Timezone and locale formatting behavior
Screen resolution / pixel ratio
These signals can often be extracted from headers and built-in browser APIs.
3.2 Active signals (collected via tests)
Some systems run small in-browser checks such as:
Canvas rendering tests (how a browser draws text/shapes)
Audio context tests (how the browser processes audio signals)
These active tests aim to capture subtle differences in rendering output that can be difficult to hide.
3.3 “Consistency checks”
Sophisticated systems don’t only ask “what signals are present?” They also ask whether signals match each other logically (for example, whether rendering behavior aligns with reported browser/OS traits).
4) The Problem: One Real Person, Many Technical Identities
A common misunderstanding is thinking:
“I’m the same user, so the website should treat me the same.”
In reality, websites often treat you as different identities when technical conditions change, such as:
Switching devices
Using different browser versions
Changing network characteristics
Running automation or scripts that alter runtime behavior
Using different profiles on the same machine
Even legitimate workflows can trigger risk systems if the website sees inconsistencies.
This is why many account management workflows require stronger identity control—especially when someone needs multiple accounts, multiple profiles, or reliable session behavior.
5) Where Antidetect Browser Technology Fits
An antidetect browser is designed to help users maintain controlled, consistent browser environments across sessions and profiles—so the “identity signals” presented to websites remain aligned with the intended profile.
From the Octo Browser site content provided, the service positions itself as an antidetect browser solution for multi-accounting and fingerprint management, including:
creating and managing multiple accounts
using “digital fingerprints” associated with real device profiles
handling multi-accounting tasks across many platforms
focusing on fingerprint spoofing and reducing ban/suspension issues
It also emphasizes profile management features and supporting infrastructure such as proxies, team permissions, and updates to the underlying browser kernel.
Why this matters
In the context of digital fingerprints, “security” doesn’t just mean encryption. It also means controlling the environment so that:
your browser behaves consistently per profile
your runtime signals match your profile intent
you avoid unnecessary identity confusion
6) What “Fingerprint Management” Usually Means
Fingerprint management is the practice of controlling the technical identity signals a browser presents.
In practical terms, it may involve:
using separate profiles that represent different “device-like” environments
keeping profile attributes stable over time
isolating sessions so behavior doesn’t leak between accounts
maintaining consistency so the platform sees a coherent identity per profile
Octo Browser’s messaging includes “High-Quality Fingerprints” and ongoing monitoring/updating of fingerprint parameters for fewer issues during account use.
Additionally, it describes built-in proxy selection inside the browser and browser stability practices intended to keep the experience smooth.
7) Real-World Risk: Fingerprinting Protections Are a Moving Target
Websites and browser ecosystems keep changing.
Case study (research signal)
Researchers have documented widespread privacy-invasive use of browser fingerprinting in online advertising ecosystems, highlighting that fingerprinting-based identification can be part of how ads adjust behavior and tracking.
Browser-side defenses also evolve
As privacy protections improve, fingerprinting becomes harder in some cases—but rarely “solves everything,” because many websites still rely on fingerprintable signals for functionality and risk control.
The key takeaway:
fingerprinting is not a one-time problem
it’s an evolving arms race between identification and protection
8) Antidetect Browser Technology for Multi-Profile Online Management
Now let’s connect the concept to practical usage.
8.1 Why multi-profile management exists
Many users and teams need to operate more than one account for legitimate reasons such as:
running separate campaigns
managing separate client accounts
testing workflows
keeping different projects isolated
However, operating multiple accounts creates an identity consistency challenge:
the website expects stability
but the user’s environment may change
and risk systems may interpret changes as suspicious
An antidetect browser approach is generally intended to help maintain per-profile coherence.
8.2 What features matter for usability
Even if fingerprinting tech is strong, account operations fail when the tool is hard to use. Octo Browser’s content highlights convenience features like:
profile management with tags, templates, and bulk actions
team permissions and action logs
configuration flexibility tied to subscription needs
fast kernel updates and stability messaging
From a reader perspective, that translates to one goal:
Reduce manual friction so you can operate reliably.
9) Proxies, Networks, and Why They’re Mentioned
Fingerprints aren’t just “device + browser.” Many risk systems also consider network patterns.
When proxy-like routing is involved, it may help align the observed IP characteristics with the intended session context. Octo Browser specifically describes a “Built-in Proxy Shop,” where proxies can be chosen directly in the browser.
Important framing:
Proxies are not a magic shield.
But in real systems, identity signals often include both network and client behavior.
So, reliable account environments typically involve more than one layer of alignment.
10) Security vs. “Avoiding Detection”: A Helpful Way to Think About It
Some people associate antidetect tools only with “hiding.” That’s an incomplete understanding.
A more constructive framing is:
Security through consistency
A website sees identity signals.
If the environment is inconsistent, it can trigger risk controls.
A managed profile environment helps ensure consistency.
Privacy through compartmentalization
Profiles and sessions can be isolated.
Data leakage across accounts can be reduced.
Octo Browser’s description includes themes like anonymity, data protection practices, and 2-factor authentication and encryption-related statements about profile passwords.
While you should always review the details directly from the provider and your own compliance requirements, the general concept is that controlled environments can reduce accidental exposure.
11) A Simple Step-by-Step Guide to Digital Fingerprint Concepts (No Tech Skills Needed)
If you want to understand this topic without diving into code, use this mental checklist:
Identify what the website can observe
browser headers, device traits, render outputs, and runtime behaviors
ongoing adaptation when browser kernels and detection systems change
In Octo Browser’s positioning, this future is represented through claims such as frequent kernel updates, stability focus, and continuous fingerprint parameter monitoring.
13) Best Practices for Anyone Exploring Fingerprint-Aware Browsing
Whether you use an antidetect browser or just want safer multi-session habits, keep these best practices in mind:
Use separate profiles for separate accounts
Avoid unnecessary environment changes during key actions
Keep your browser consistent
Plan for updates (both browsers and websites evolve)
Prefer tools and workflows that provide visibility
action logs, permission controls, and stable operations help teams
From Octo Browser’s content, features like tags/templates, team management permissions, and action logs are positioned as part of operational control.
14) Frequently Asked Questions (Simple and Direct)
Is a digital fingerprint the same as a cookie?
No. Cookies are stored data you can often delete. Fingerprints are derived from browser/device signals that may persist even if cookies are cleared.
Why do some login attempts get flagged even when I’m the real user?
Because risk systems often evaluate multiple signals together and may detect inconsistencies between sessions, devices, or technical behavior.
What does an antidetect browser help with?
It’s generally intended to support multi-profile operations by helping keep identity-related signals more consistent per profile. Octo Browser describes this approach as “antidetect browser for multi-accounting” with fingerprint management.
Conclusion: Antidetect Browser Technology and the Next Era of Online Identity Control
Digital fingerprints are becoming a central part of how the modern web understands and evaluates user sessions. Fingerprinting systems often combine many signals—passive attributes like screen size and locale with active rendering behaviors like Canvas or WebGL—into a powerful identity representation.
Because those signals can change across devices, profiles, and runtime configurations, legitimate multi-account workflows can face friction when identity appears inconsistent.
Antidetect browser technology addresses this challenge by enabling controlled, profile-based environments designed to keep fingerprint signals coherent and consistent—supporting secure online management at scale. Based on the provided Octo Browser content, the service positions itself around multi-accounting, fingerprint management, profile handling, proxies, teamwork permissions, stability, and kernel update practices.
In short: as online platforms continue to rely on identity signals beyond cookies, the future of secure online management is moving toward structured profile control and fingerprint-aware browsing—and that’s the core promise of an antidetect browser approach.
In this post, I will talk about why Tigoals Live Score updates are faster than most football apps.
Football apps have a weird problem. They are free, everyone has three copies and somehow they are always a bit ‘out of the loop’. You are watching a match and your cell phone beeps with the notification of a goal two minutes after you saw it go in.
Or you’re not watching, and you check the score and realize that in 4 minutes the app hasn’t been updated, and you don’t know if what you’re looking at is up to date. That lag might sound small, but in football, two minutes is an eternity, and tigoals live football handles this better than most dedicated score apps manage to.
Why Apps Fall Behind
Most football apps push score updates through notification systems that add delays before anything reaches your screen.
The goal occurs, data is captured, it passes through the server of the app, it is processed, added to an update queue containing updates from dozens of other games and finally appears on the user’s phone. Every step in that chain adds seconds. Multiply that across a busy Saturday with thirty matches running simultaneously, and those seconds stack up into something noticeable.
What Happens on a Busy Saturday
Eight matches kicking off at three o’clock. Goals are going in everywhere at once. Your app is trying to process updates from all of them simultaneously, and the system slows under that load.
The matches you care about most are competing with updates from games you have never heard of for the same processing bandwidth. The result is that the score you check after hearing crowd noise from your neighbor’s television is already two minutes old before it appears on your screen.
Browser-Based Updates Move Differently
Opening a live score page in a browser rather than checking an app changes how the updates reach you. The page pulls information directly rather than waiting for a notification system to push it through.
When you refresh or when the page updates automatically, you are getting current data rather than whatever was sitting in a queue waiting to be delivered. That difference in how information travels is why browser-based score tracking often feels snappier than app notifications even when the underlying data source is similar.
Following a Match You Cannot Watch
You are at dinner, phone face down on the table, sneaking looks every few minutes. The situation where live score speed matters most is exactly this one. You check Tigoals live football and the score shows nil-nil in the sixty-eighth minute. You check again four minutes later, and it shows one-nil.
Midway through that stretch of time, a score occurred. The moment matters. Knowing right away feels necessary, even if others learned much earlier. Information lags behind events. That delay creates distance. Closeness comes from timing. Not waiting keeps you present. Real-time awareness shapes experience differently. Delayed knowledge lands flat.
Running Several Matches Simultaneously
There are six matches on Tuesday, Champions League shows, in two start times. You wish to monitor every one of them without switching between multiple applications or opening six tabs.
Having everything on one page that updates in real time across all matches simultaneously is genuinely more useful than any collection of individual app notifications arriving in random order on your lock screen throughout the evening.
The Notification Problem With Apps
App notifications for goals sound useful in theory. In practice, your phone buzzes constantly during a busy fixture schedule, and half the notifications are for matches you have no interest in. Turning off notifications solves that problem, but then you lose the live update function entirely.
Checking a live score page on demand when you actually want to know something is a cleaner experience than managing a notification system that either gives you too much or too little, depending on how you have it configured.
When the Score Actually Matters
In the last ten minutes of a match, your team needs to win while a rival plays somewhere else simultaneously. Every single update in both matches carries enormous weight.
Both of these can be seen on the same page in Tigoals live football, and the updates are fast enough that you don’t spend a lot of time wondering if what you are seeing is up to date. The confidence in those moments when it counts is what truly sets a good live score feed apart from one that can be relied upon only for casual viewing.
A slight detail like fast score updates becomes so important when you’re racing titles or fighting for relegation, and each minute of information is worth it.
This post will show you how to build a strong credit score.
In today’s financial landscape, your credit score is crucial in many aspects of your life. From securing loans and credit cards to renting an apartment or even landing a job, a good credit score can open doors and save you money.
On the flip side, a poor credit score can create significant obstacles and cost you dearly in the long run. This guide will walk you through the essentials of building and maintaining a strong credit score, empowering you to take control of your financial future.
Understanding Credit Scores
Before diving into strategies for improving your credit score, it’s important to understand what a credit score is and how it’s calculated.
What is a credit score?
A credit score numerically represents your creditworthiness, typically ranging from 300 to 850. The higher your score, the more likely you will be approved for loans and credit cards with favourable terms.
How is a credit score calculated?
While there are several credit scoring models, the most widely used is the FICO score. FICO scores are calculated based on five main factors:
Payment history (35%)
Credit utilization (30%)
Length of credit history (15%)
Credit mix (10%)
New credit inquiries (10%)
Understanding these factors is key to developing strategies for improving your credit score.
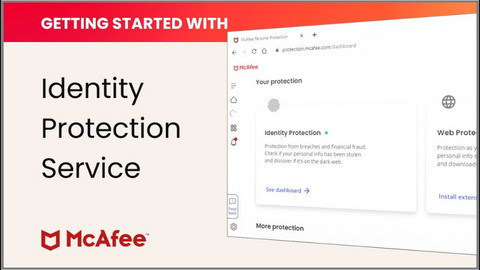
Top Identity Protection Deals To Build Strong Credit Scores
McAfee Identity Protection
Total protection from identity theft and financial crimes.
Total protection from identity theft and financial crimes. Show Less
Norton LifeLock Identity Advisor
Your best solution to protect your personal information from data leaks.
Your best solution to protect your personal information from data leaks. Show Less
55% OFF
Incogni
Incogni wipes off your personal information from data brokers.
Incogni wipes off your personal information from data brokers. Show Less
BFDEAL25
DeleteMe
DeleteMe is a service provided by Abine that helps users remove their personal information from data brokers and other...Show More
DeleteMe is a service provided by Abine that helps users remove their personal information from data brokers and other websites to protect their privacy online. Show Less
Social Catfish
Social Catfish is an online service that helps individuals verify and investigate the identity of people they meet...Show More
Social Catfish is an online service that helps individuals verify and investigate the identity of people they meet online, including potential scammers and catfishers. Show Less
Surfshark Alert
Surfshark Alert is a real-time data breach protection tool that safeguards your email accounts, passwords, personal...Show More
Surfshark Alert is a real-time data breach protection tool that safeguards your email accounts, passwords, personal identification numbers, and credit cards from cyber-attacks. Show Less
OmniWatch
Safeguard your identity with OmniWatch, the comprehensive identity theft protection service that provides proactive...Show More
Safeguard your identity with OmniWatch, the comprehensive identity theft protection service that provides proactive monitoring, dark web surveillance, and expert assistance in case of a breach. Show Less
AVG BreachGuard
AVG BreachGuard shields your online data from leaks and breaches, like a vigilant bodyguard for your digital life.
AVG BreachGuard shields your online data from leaks and breaches, like a vigilant bodyguard for your digital life. Show Less
Avast BreachGuard
Avast BreachGuard is a privacy tool designed to protect personal information online by preventing data breaches...Show More
Avast BreachGuard is a privacy tool designed to protect personal information online by preventing data breaches, removing personal data from data brokers, and providing real-time alerts for compromised data. Show Less
WhiteBridge AI
WhiteBridge AI is your digital identity detective — an AI-powered tool that uncovers, verifies, and organizes...Show More
WhiteBridge AI is your digital identity detective — an AI-powered tool that uncovers, verifies, and organizes everything the internet says about a person into one powerful, insightful report. It transforms scattered online chaos into a clear story you can trust, helping you protect your reputation, make smarter decisions, and see people as they truly are. Show Less
Privacy365
Privacy365 is a service that removes your personal information from data brokers and people search websites while...Show More
Privacy365 is a service that removes your personal information from data brokers and people search websites while continuously monitoring for new exposures. By cleaning up your digital footprint, it helps protect you from identity theft, doxxing, and unwanted contact. Show Less
NordProtect
NordProtect is a comprehensive identity theft and cyber protection service provided by Nord Security. It provides...Show More
NordProtect is a comprehensive identity theft and cyber protection service provided by Nord Security. It provides all-around protection against identity theft, including credit monitoring, dark web surveillance, security alerts, identity theft recovery, cyber extortion protection, and online fraud coverage. Show Less
Steps to Build a Good Credit Score
1. Pay Your Bills on Time
Payment history is the single most important factor in determining your credit score. Consistently paying your bills on time demonstrates responsibility and reliability to lenders.
Tips for timely payments:
Set up automatic payments for recurring bills and travel expenses
Use calendar reminders for due dates
Consider paying bills twice a month to avoid missing due dates
2. Keep Your Credit Utilization Low
Credit utilization refers to the amount of credit you use compared to your credit limits. Aim to keep your utilization below 30% across all your credit cards and lines of credit.
Strategies to lower credit utilization:
Pay down existing balances
Request credit limit increases
Spread purchases across multiple cards
Make multiple payments throughout the month
3. Maintain a Long Credit History
The length of your credit history contributes to your credit score. Keep your oldest accounts open, even if you don’t use them frequently.
Ways to build credit history:
Become an authorized user on a family member’s long-standing account
Open a secured credit card if you’re new to credit
Keep old accounts open, making occasional small purchases to keep them active
4. Diversify Your Credit Mix
A mix of different types of credit (e.g., credit cards, personal loans, mortgage) can positively impact your score. However, don’t open new accounts for this purpose if you don’t need them.
Examples of different credit types:
Revolving credit (credit cards)
Installment loans (personal loans, auto loans)
Mortgage loans
Student loans
5. Limit New Credit Applications
Each time you apply for credit, a hard inquiry is recorded on your credit report. Too many inquiries in a short period can negatively impact your score.
Tips for managing credit inquiries:
Only apply for credit when necessary
Research and compare offers before applying
Take advantage of pre-qualification tools that use soft inquiries
6. Monitor Your Credit Reports Regularly
Regularly checking your credit reports allows you to spot errors or fraudulent activity that could hurt your score.
How to monitor your credit:
Request free annual credit reports from AnnualCreditReport.com
Use credit monitoring services offered by credit card companies
Use identity protection tools like Incogni, DeleteMe, or OmniWatch Identity to safeguard your personal information.
7. Address Negative Items on Your Credit Report
If you find errors or outdated information on your credit report, take steps to have them corrected or removed.
Steps to address negative items:
Dispute errors with the credit bureaus
Negotiate with creditors to remove negative items in exchange for payment
Consider working with a reputable credit repair company for complex issues
8. Use Credit Responsibly
Responsible credit use is key to building and maintaining a good credit score. This means using credit when necessary but avoiding overreliance on borrowed money.
Responsible credit habits:
Only charge what you can afford to pay off
Pay more than the minimum payment whenever possible
Avoid maxing out credit cards
Use credit for planned purchases rather than impulsive spending
9. Consider a Secured Credit Card
If you’re new to credit or rebuilding after financial difficulties, a secured credit card can be an excellent tool for establishing a positive payment history.
Benefits of secured credit cards:
Easier to qualify for than traditional credit cards
Reports to major credit bureaus
It helps build a credit history
Can graduate to an unsecured card with responsible use
10. Become an Authorized User
Being added as an authorized user on someone else’s credit card account (preferably someone with a long history of responsible use) can help boost your credit score.
Tips for becoming an authorized user:
Choose someone with a strong credit history
Ensure the primary account holder makes timely payments
Verify that the card issuer reports authorized user activity to credit bureaus
11. Keep Old Accounts Open
The length of your credit history impacts your score, so keeping old accounts open can be beneficial, even if you don’t use them frequently.
Strategies for maintaining old accounts:
Make small, occasional purchases on old cards
Set up recurring payments for small bills on older accounts
Store old cards safely to prevent fraudulent use
12. Use Credit-Building Tools
Several tools and services are designed to help individuals build or improve their credit scores.
Credit-building tools to consider:
Credit-builder loans
Rent reporting services
Experian Boost (reports utility and streaming service payments)
13. Manage Student Loans Responsibly
For many young adults, student loans are their first experience with credit. Managing these loans responsibly can help establish a positive credit history.
Tips for managing student loans:
Make payments on time
Consider income-driven repayment plans if struggling
Look into loan forgiveness programs if eligible
14. Avoid Common Credit Mistakes
Awareness of common pitfalls can help you avoid actions that could negatively impact your credit score.
Mistakes to avoid:
Closing credit cards with long histories
Co-signing loans for unreliable borrowers
Ignoring credit card statements
Settling debts without understanding the credit implications
15. Seek Professional Help When Needed
Don’t hesitate to seek professional assistance if you’re struggling with debt or complex credit issues.
Resources for professional help:
Credit counseling agencies
Financial advisors
Debt consolidation services
Bankruptcy attorneys (as a last resort)
16. Protect Your Identity
Identity theft can wreak havoc on your credit score. Taking steps to protect your personal information is crucial for maintaining good credit.
Identity protection strategies:
Use strong, unique passwords for all financial accounts
Enable two-factor authentication when available
Be cautious about sharing personal information online
Consider using identity protection tools like Incogni, DeleteMe, or OmniWatch Identity
These tools offer various services to help safeguard your personal information:
Incogni: Helps remove your personal information from data broker databases, reducing the risk of identity theft and unwanted marketing.
Incogni
Incogni wipes off your personal information from data brokers.
Incogni wipes off your personal information from data brokers. Show Less
DeleteMe: Specializes in removing personal information from public records and people-search websites.
DeleteMe
DeleteMe is a service provided by Abine that helps users remove their personal information from data brokers and other...Show More
DeleteMe is a service provided by Abine that helps users remove their personal information from data brokers and other websites to protect their privacy online. Show Less
OmniWatch: Offers comprehensive identity monitoring and protection services, including dark web monitoring and identity theft insurance.
OmniWatch
Safeguard your identity with OmniWatch, the comprehensive identity theft protection service that provides proactive...Show More
Safeguard your identity with OmniWatch, the comprehensive identity theft protection service that provides proactive monitoring, dark web surveillance, and expert assistance in case of a breach. Show Less
While these tools can be valuable additions to your identity protection strategy, it’s important to research and choose the one that best fits your needs and budget.
17. Be Patient and Persistent
Building a good credit score takes time and consistent effort. Don’t get discouraged if you don’t see immediate results.
Long-term strategies:
Set realistic credit score goals
Celebrate small improvements
Stay committed to responsible credit habits
Regularly review and adjust your credit-building strategy
18. Educate Yourself Continuously
The world of credit and finance is always evolving. Staying informed about changes in credit scoring models, new financial products, and best practices can help you make better decisions.
Ways to stay informed:
Follow reputable financial news sources
Attend financial literacy workshops
Read books on personal finance and credit
Join online communities focused on credit-building
19. Plan for the Future
As you build your strong credit score, it’s important to consider how a good credit score fits into your broader financial goals.
Future considerations:
Saving for major purchases (e.g., home, car)
Building an emergency fund
Planning for retirement
Investing for long-term growth
Conclusion
Building a strong credit score is a journey that requires patience, discipline, and knowledge. By understanding how credit scores work and implementing the strategies outlined in this guide, you can take control of your financial future.
Remember that good credit is just one aspect of overall financial health. Combine these credit-building strategies with sound budgeting, saving, and investing habits to create a solid foundation for long-term financial success.
Whether you’re just starting to build credit or working to improve an existing score, the key is to stay committed to responsible financial habits. With time and consistent effort, you can achieve and maintain a credit score that opens doors to better financial opportunities and peace of mind.
As you embark on your credit-building journey, don’t forget to protect your hard-earned progress by safeguarding your personal information. Tools like Incogni, DeleteMe, and OmniWatch Identity can provide an extra layer of protection against identity theft and fraud, helping to ensure that your credit score accurately reflects your financial responsibility.
Remember, your credit score reflects your financial habits and responsibility. By making informed decisions and staying committed to your goals, you can build a strong credit score that will serve you well throughout your financial life.
We are in the new millennium, where technology has led to several innovations and inventions at large. We can now install cameras at home to monitor everything from any place and at any time. Hidden nursing cameras are now used to monitor our loved ones in the nursing facilities.
But then, can I install a hidden camera in a nursing home? This project will highlight largely whether it is right to make such installations. The reader will also learn the steps to take whenever they find any form of abuse and neglect in the nursing rooms.
Can I Install A Hidden Camera In A Nursing Home?
Cameras in nursing homes are employed to monitor the common points around the facility. These can be at the entry points, parking lots, and other common areas within the facility.
At times, these cameras may be installed in the residents’ rooms whenever there is a need to do so. The cameras provide people with maximum safety for their loved ones in these places at large.
However, not all nursing homes allow such installations. Directors of such facilities fear that people might invade the residents and staff’s privacy at large. This leads most people to resort to fixing hidden cameras to watch over their loved ones from anywhere and anytime. So, can I install a hidden camera in a nursing home?
Yes, you can install them. However, the installation of hidden cameras in nursing homes has legal and privacy implications at large. These cameras are mostly installed by parents who suspect forms of abuse and neglect.
This provides a parent or guardian peace of mind wherever they are. Even if there is no form of abuse and neglect, hidden cameras help ensure caregivers use proper techniques that don’t cause residents’ problems.
On the other hand, hidden cameras are fond of raising privacy concerns among caregivers and residents at large. Most residents find it awkward to be monitored whenever they are doing particular activities such as bathing and changing attire.
Everyone needs privacy, and by installing such cameras, you would have trampled on the privacy of every person going in and out of that place.
Is the installation of a mini hidden camera for nursing homes permitted by administrators? This is a good question, and we are going to provide the right answer for it. Permits are provided depending on the particular facility. A few facilities have banned hidden cameras or, at times imposed requirements for use.
Other states have allowed such installations in recent days over concerns of elder abuse in several nursing homes. However, the states that permit this installation require families to agree with the residents and roommates before installing them.
Besides this, you should contact an expert attorney to guide you through the legal and private implications before installing hidden cameras.
Step To Take If You Suspect Abuse And Neglect In Nursing Homes
In case you suspect any form of abuse or neglect in the nursing home, there are steps you should undertake to get justice. First, you are required to gather evidence of the events that happened to support the claim you plan to put across.
These can be in the form of photographs of the physical occurrences, such as broken bones, lacerations and cuts, and other things, such as unexplained medical problems and gradual loss of weight.
These are the things you will present to your attorney seeking justice in the form of abuse and neglect of your loved ones in a nursing home.
However, you won’t like such things to happen to your loved ones at any time again. There are several things to stop cases of abuse and neglect from happening, and hold a particular facility accountable if they occur.
Such things include:
Ensure you report the allegations immediately they occur to the nursing facility. They should take action on it fast. In case they don’t, consider getting justice anywhere else.
Take a report of your allegations to the state department that investigates such issues. They will act swiftly to provide a solution to the problem.
In the case of developing a medical problem, consider seeking medical opinions. Seek a medical practitioner’s help to examine the issue immediately. The examination provides evidence of the possibility of any form of abuse and neglect in the nursing home.
Visiting your loved one should be a habit for you. This reduces cases of abuse and neglect by the facility staff.
In case of sudden weight loss, track them, and seek a professional guide about the incidence. Such changes might serve as evidence of the form of abuse and neglect in a nursing facility.
Families whose loved ones spend time in nursing homes benefit a lot from installing hidden cameras in those facilities. However, such installations do not provide any form of advantage to staff members and residents, and roommates alike who need privacy at large.
Several states are now considering the installation of hidden cameras in nursing homes at large. However, since this doesn’t benefit all parties, it is better if lawmakers strike a balance between residents’ privacy and the safety of people in these facilities.
Few states have gone through this issue and tried to fix the problem. They have aimed at balancing both parties to benefit from what they pass as law.
For instance, states have permitted installing them, but then they get turned off periodically. This is when residents and roommates are changing or even when bathing. This way, both safety and privacy have been resolved.
Can I install a hidden camera in a nursing home? Abuse and neglect happening in nursing homes have raised issues in the recent past. Some facilities don’t allow such installation for fear of invading their staff and residents’ privacy.
However, as days pass, this is slowly becoming law in different states at large. Installation of hidden cameras in nursing homes provides people peace of mind all through about their loved ones.
Are you a movie fanatic? This piece is for you! In this article, we bring you the best torrent websites for movies in 2026.
Finding an excellent torrenting site is quite challenging due to the frequent clamp down on torrent websites. Hence, a fully functional torrenting site might become unavailable within a space of 24 hours.
As a Hollywood or Bollywood enthusiast, you are probably familiar with a number of torrent sites, which provide access to top quality movies online. These sites afford movie lovers the opportunity to watch their favorite Hollywood/Bollywood movies hassle-free on their smartphones and PCs.
However, as at the time of compiling this list, we have compiled a list of the top torrent websites that are still functional and much loaded to meet your torrenting needs. Follow through with rapt attention.
What Is A Torrent File?
A torrent file is a computer file that contains information about files and folders distributed over a torrent network. It is like a table of content that helps users download content using the P2P file-sharing system.
A torrent file must have the .torrent file extension and can only be opened with a torrent client.
To open a torrent file:
Copy a torrent file link from a torrenting site
Launch your torrent client
Open a new torrent file window
Paste your torrent file link
Then, confirm that it has the right file content you want to download before clicking OK.
What Is A Torrent Site?
A torrent site is a website that contains an index of torrent files users can use to download content ( books, movies, music, TV shows, software, etc.) from other users on the torrent network.
Torrent files downloaded from torrent sites do not hold web content; rather, it helps you find other torrent users uploading or downloading the same content on the BitTorrent network using a BitTorrent client.
CyberGhost VPN is a VPN with over 7000 high-speed servers and a friendly interface for beginner torrent users. There’s a big ‘Torrent Anonymously’ button that connects you automatically to the fastest torrenting-optimized server.
Ivacy VPN is an easy-to-use VPN with fast servers that guarantee good torrenting speed. It also offers additional features, including a password manager, port forwarding, etc.
TorGuard, as the name implies, is a torrenting-optimized VPN with all servers optimized for anonymous torrenting. It also boasts of features that guarantee speed, privacy, and security.
PIA has over 10,000 P2P-optimized servers. In addition, it has a Port forwarding feature that guarantees fast and stable torrenting speed by bypassing NAT Firewalls.
PureVPN has 6,500 VPNs, all of which support speedy torrenting. In addition, PureVPN offers many other features, including port forwarding, dedicated IP address, DDoS, and more.
ProtonVPN is a privacy-focused VPN provider with over 17 torrenting-optimized P2P servers. It has great download speeds that can clock almost 700Mbps, making it one of the best options for torrenting.
EDITOR’S NOTE: Neither we nor any of the VPN services mentioned in this post support illegal torrenting. Also, Torrents should be used only for legal file sharing and downloading.
What Are The Best Torrent Websites For Movies
1. Pirate Bay
Pirate Bay is the most popular torrent website for movie fanatics. And it serves as the ultimate go-to for millions of Hollywood and Bollywood lovers across the globe.
The site provides access to tons of torrents; offering access to high-quality HD movies. Furthermore, you get access to new movies, even before full release.
Pirate Bay is home to a diverse range of torrents. The torrent king has a large repository of old and new movies torrent files.
As a movie fanatic, Pirate Bay is asafe torrent website you’d definitely want to check out.
This is another popular torrent website, which offers myriads of torrents to movie lovers across the globe. It is one of the major torrent hubs for accessing high-quality Bollywood (and Hollywood) movies.
The interesting thing about this site is that; it serves as a “search engine”, which provides direct access to other torrent sites. Put aptly, you can get torrents from other torrent sites viaTorrentz2.
Torrentz2 has a huge library of old and new movie torrent files from diverse sources. It is also a great torrent site for all torrent categories.
TorentDB is a movie torrent website, which hosts myriads of Hollywood movie torrents. It is one of the favorite sites of Hollywood fanatics, offering access to classic and modern Hollywood movies.
If you’re in need of a good torrent site for Hollywood movies, TorrentDB is a website to check out.
4. Torrents.me
Torrents.me is another popular torrent site. It is similar to Torrentz2, in that it also serves as a “search engine” for movie torrents. With this site, you’re provided access to over five hundred torrent sites. This ensures that you’re not limited by server downtime and the likes.
Essentially, you can access virtually all your favorite Bollywood and Hollywood movies via Torrents.me.
5. I337x
I337x is a renowned download hub for movie torrents, particularly torrents for Bollywood movies. The site is fairly easy to navigate, with a sizable number of torrents, all of which are available for free.
In addition, 1337x boasts a diverse array of contents and an easy-to-use interface that lets users easily find their desired movie torrent file.
If you’re a core Bollywood fan, check out their website today.
6. SeedPeer
This torrent website stands out primarily due to its huge collection (of torrents); however, it houses more of Bollywood movie torrents. Nonetheless, there are still innumerable Hollywood torrents on offer.
Check outSeedPeer today – for your Bollywood (and Hollywood) movie torrents.
7. ExtraTorrents
ExtraTorrents is another excellent torrent site, which doubles as a search engine for movie torrents. The site provides visitors with the flexibility of exploring numerous torrent sites on the internet. With this, visitors are able to access hundreds of torrent sites, and thousands of movie torrents for free.
8. KickAssTorrents
KickAssTorrents (KAT) offers tons of high-quality movie torrents – providing access to thousands of Hollywood and Bollywood movies. Navigate to theirwebsite to download your favorite movie torrents now.
RARGB’s user-friendly interface makes it easy for users to find old and new movies; it gets blocked often.
10. YTS
YTS is commonly rated as the best movie torrent site for its diverse collection of old and new movie torrents.
11.TorrentDownloads
TorrentDownloads is one of the best torrenting sites for downloading movies, TV shows, games, etc. However, this site is not accessible in the UK without the use of a good VPN service.
12.Zoogle
Zoogle is a torrent search engine for movies and other file types, including TV shows, music, images, ebooks, etc.
13.LimeTorrents
LimeTorrents has an easily navigable interface that makes it easy for new users to find their way. It is a torrent site with a big database of movies and TV shows.
14.TorLock
TorLock is one of the safest torrenting sites where users download verified torrenting files without fearing malware infection.
15.Ru Tracker
This is a Russian torrent site that blocks out ads. It is home to a diverse range of free indie content.
16.WatchSoMuch
WatchSoMuch is a mobile-friendly movie torrent site with an amazing array of movie collections.
17.EliteTorrents
Elite Torrents is a favorite Spanish torrent site with tons of South American movie content.
18.TorrentFunk
TorrentFunk has a sleek appearance that lets you search and navigate the site easily. It is home to large collections of movies, anime, software, and adult videos.
19.Nyaa
Nyaa is a Japanese torrent site that features movies and anime content from Japan, China, and Korea.
20.SolidTorrents
SolidTorrents is a torrent site with a clean interface and a search engine to make it easy to locate any type of torrent file. Its movie category features diverse collections of old and new movie torrents.
21.iDope
iDope is a torrent site with magnet links. It also features several mirror links with which you can access the website. However, this site is accessible to users in the UK, Australia, Denmark, and India using a VPN.
22.TorrentGalaxy
TorrentGalaxy is a multipurpose torrenting site with a vast repository of movies, music, games, software, and ebook content.
23. DirtyTorrents
DirtyTorrents is a torrent search engine that features the most popularly downloaded movies, and TV shows, in the last 24 hours.
24. YourBittorent
YourBittorrent is a torrenting site that features recent torrent searches across several torrent sites. It also has a movie repository as well as a search bar for searching favorite movie titles.
25.ExtraTorrent
ExtraTorrent.it is the replacement site for ExtraTorrent.cc. It has a great array of movie collections in several categories and limited ad display compared to other torrent sites.
26. GloTorrents
GloTorrents is a favorite movie torrent site that displays torrent links to contents and additional details, including file size, seeders, leechers, and link health.
27.Demonoid
Navigating Demonoid may not be easy due to the cluttered interface, but using keyword search to locate your movie torrent file is the fastest way to navigate Demonoid content.
28. Torrent9
Torrent9 is a French torrenting site for French lovers. The site is predominated with content in French, although you will find amazing content in several categories.
29.MagnetDL
MagnetDL has a clean interface with well-arranged links that serve as menubar directly at the top and a prominently placed search engine for locating torrent files without the stress of rummaging through tons of content.
30.EZTV
EZTV is the oldest and most functional movie torrent site where you can find good classical movies and TV shows dating way back to the 80s and 90s.
31. IPTorrents
IPTorrents is a private torrent site accessible after making donations. It has an active forum and an extensive movie library.
32. Torrend
Torrend features a list of over 600 torrent sites arranged in categories; hence you can easily find the best torrent site for movies using this great torrent search engine.
33. TorrentSeeker
TorrentSeeker is a torrent search engine that indexes movie search results according to popularity, niches, and languages.
34. ISOHunt
ISOHunt has a clean interface with no obstructive ads. It is one of the best torrent sites for downloading all categories of movies.
35. BitLord
BitLord is a torrenting site with a feature-rich interface. The site features movie collections suitable for families, and it encourages all users to report adult content found on the site.
36.Pirateiro
Pirateiro is a Brazillian and Portuguese torrent search engine with amazing Brazillian, Spanish, and Portuguese movies. The site also supports multiple languages, including English.
37. BittorentAM
BittorrentAM has vast repositories of torrents that cut across several categories, including movies, anime, and TV shows.
38. Bit Torent Scene
Bit Torrent Scene is one of the best movie torrent sites with large repositories of movie genres. The site has several mirror URLs and IPs, making it a difficult torrent site to ban.
39. DivxTotal
DivxTotal is a movie-oriented torrenting site with one of the largest collections of High-Density Spanish movies.
40.NoNameClub
This is a Russian torrent site with great collections of movies. It also has a forum where members can discuss any topic outside of torrenting.
41. Tokyo Toshokan
Tokyo Toshokan is a Japanese movie torrenting site with predominantly Japanese content.
42. P2pBG
P2pBG brings innovation and fun to torrenting. Aside from downloading recent and classical movies, it has an active community of users participating in fun activities online.
43. ArabP2P
ArabP2P is one of the oldest movie torrenting sites. The site hosts large repositories of movie categories, including great content from the Arabian world.
44. ilCorSARoNeRo
This is a torrenting site with many free Italian movie torrents.
45. Cinemagedon
This is a private movie torrent site with varied categories of movies, including X-rated movies.
46. Partis
Partis is a Slovenian torrent tracker with incredible download speed. The site is home to the latest movie torrents.
47. SuperBits
SuperBits is a Swedish torrent site that requires new users to register and become a member of its forum before gaining access to free movies.
These torrenting sites are known to have excellent Hollywood movies for torrenting:
1. The Pirate Bay
The pirate bay is one of the oldest torrenting sites available. You will find pirate bay’s millions of torrents quite breath-taking. However, to make download easy, Pirate Bay has a simple interface that makes navigation easy, coupled with the fact that its millions of movie collections are in categories for easy navigation and download.
Although Pirate Bay is in its 15th year, it has experienced several turbulent times with several changes in its domain name. Presently, pirate bay uses the ‘.org.’ domain name.
2. YTS.It
YTS is a torrenting site well known for releasing movies and TV shows from around the world’ hot on the list’. It is also a preferred torrenting site for its small file size, and less buffering while streaming.
Although YTS torrenting site has been in three US lawsuits as of recent and has signed to pay ‘damages’ to a producer, it nonetheless remains online for movie lovers in search of newly released films around the globe.
3.LimeTorrents
LimeTorrents has a simple and minimalistic design that makes it quite easy for new users to find their way on the torrenting site. It also hosts several new releases in its movie and TV shows collections.
Although LimeTorrents ranks amongst the most visited torrenting sites with its large follower base, it has, however, experienced its fair share of legal tribulations and domain seizures within ten years of its existence.
4.1337X
1337X has a simple interface with its collection of movies and TV shows organized into categories for smooth navigation. Recently, the torrenting site went through an overhaul to improve its security and layout.
In addition, 1337x is one of the most popular torrenting sites in the world known for helping torrent seekers find new movies. In 2014, the site was delisted from Google’s search index after a series of complaints were bothering copyright infringement.
PopCornFlix is one of the biggest Holywood movie torrenting sites. However, this service is best accessed with a VPN.
6. ArenaBG
Arena BG is a Hollywood torrenting site with an active community. It also serves as a torrent tracker to find any Hollywood movie of your choice.
7. TorrentBox.Sx
This is one of the best Hollywood torrent sites with a well-designed interface. However, you must join its user community to access its vast content repositories.
8. BigFanGroup
BigFanGroup is a source of verifiable Hollywood movie torrents and other categories of torrent files.
9. BitNovaTorrent
BitNovaTorrent is a reliable Hollywood movie torrent with an old-school layout and a vast collection of old and new movies.
10. Torrents2Download
Torrents2Download is a favorite for Hollywood movies and games.
11. Baibako
Baibako is a mobile-optimized, semi-private torrent tracker for Hollywood movies. The site also boasts of an active community of users.
12.Public Domain Torrent
Public Domain Torrent offers a fast download speed for free Hollywood movie torrents.
13. YGG
YGG is a movie torrent site with awesome browsing, search features, and vast categories of movie collections.
14. TopNow
TopNow is a torrent site with one of the most attractive interfaces and well-categorized movie collections that includes Hollywood Action, Drama, Horror, Comedy, etc.
15. MySpleen
MySpleen is a private torrent tracker with great Hollywood content from the 80s and 90s, as well as recent movies and other categories of torrent files.
16. HD-Space
HD-Space torrent site with a clean and less-cluttered interface. It is a favorite movie torrent site for recent Hollywood movies.
17. HD-Area
This is a safe Hollywood movie torrent site with an SSL certificate. You’re expected to register and obtain your login details before gaining access to tons of Hollywood movie torrents available.
18.iBit
iBit is a movie torrent site with a colorful home page and a large navigation icon that makes navigation easy. Although the site is bugged with adverts, it hosts great Hollywood movie content.
19. Bluetopia
Bluetopia is a torrent site with a rich graphic interface. The site boasts of great Hollywood content. However, you must join its active community before gaining access to its vast torrent repositories.
20.CinemaZ
Here is a private torrent tracker with large repositories of Hollywood movies that cut across various genres.
21. HDtime
HDtime is one of the most popular Chinese torrent sites with an amazing collection of Chinese movie torrents. The site also boasts of an active community of users.
22. Broadcasthe.Net
BTN is a torrent site with one of the largest collections of Hollywood movie files as well as vast repositories of torrent file categories.
23. ToTheGlory
TTG is a safe torrent site with a large collection of free Hollywood movies.
24. AlphaRatio
AlphaRatio is a free torrenting site with amazing collections of Hollywood movies, TV shows, music, and other torrent file categories. However, membership to this torrenting tracker is strictly by invitation.
25. RevolutionTT
Revolution TT is one of the oldest torrenting sites with free Hollywood movie files.
26. FastTorrent
FastTorrent is a Russian public torrent tracker that hosts a large collection of Hollywood movies.
27. Otorrents
Otorrent torrent site has a responsive user interface and many features that make navigation easy. It has one of the largest collections of Hollywood movies that cut across all movie genres.
28. AltTorrent
AltTorrent has a mobile-friendly site and magnet links to awesome Hollywood collections.
29. Archive
This is a public, not-for-profit collection of free Hollywood movies, music, books, etc.
30. TASVideos
TASVideos has a simple user interface and large collections of recent Hollywood movies and games.
31. LegitTorrents
Legit Torrents has an active community you’re not compelled to join. The torrent site has a simple and colorful page with tons of old and new Hollywood content.
What Are The Best Bollywood Torrenting Sites?
Listed below are the best torrent websites for Bollywood movies. They also offer you an excellent collection of Hollywood movies and TV shows for torrenting.
1. 99HDFilms
99HDFilms is a Bollywood torrenting site. It offers you a unique selection of Bollywood and TV shows. On this torrenting site, you can find several categories of Bollywood movies as well as other movie categories dubbed in Hindi. Its high-quality HD resolution and the navigable interface make it a favorite amongst Bollywood torrent seekers.
2. Bolly2Tolly
Another Bollywood torrenting site on our list is Bolly2Tolly. It is one of the hottest torrent download sites for the latest Bollywood movie collections and TV shows. This torrenting site has a vast array of Bollywood movies in English, and several local languages, as well as Hindi-dubbed versions of Hollywood movies. Also, the site has an A-Z index of film, making it easy to search through thousands or millions of movie collections.
3. Besthdmovies
Aside from having one of the most extensive libraries of classic and lately released Bollywood movies, this torrenting site also boasts of vast collections of Hollywood movies and other categories of great films from around the world.
The Bollywood torrenting site indexes its movie collections based on year of release, action, adventure, animated, comedy, Hindi-dubbed movies, and other genres of movies. Hence, you can navigate its vast collection of movies without much effort in finding your desired Bollywood movie.
ArenaBG is a Bulgarian BitTorrent tracker based in Texas. The torrent website is noted for its huge Bollywood repository.
5. YourBittorent
YourBittorrent is a sister site from mybittorrent. The torrent tracker is known for having a large library of Bollywood movies.
6. Rutracker
This is the largest Russian torrent tracker with different choices of Bollywood movies
7. MejorTorrent
This is a Spanish torrent site with tons of Bollywood content. However, the site does not have a magnet link.
8. 3dl.tv
3dl.tv is a German torrent site with thousands of links to Bollywood movie torrent files.
9. 4Movierulz
4Movierulz torrent site is a torrent tracker with thousands of magnet links to Bollywood movies.
10. TorrentBox
This is a torrent search engine with links to Bollywood torrent sites.
11. Kick Ass Torrents
This is one of the oldest and most reliable sources of Bollywood movie torrents.
12. Bolly2Tolly
This is a Bollywood and Tollywood movie torrent site.
13. Cataz
Cataz is a torrent tracker for all types of Bollywood content.
14. Ganool
This is a torrent site with content from Asian countries, including India and Bangladesh.
15. MoviezWap
MoviezWap is a torrent tracker for downloading all types of movies, including Bollywood.
16. DVDPlay
DVDPlay is a torrent tracker for streaming free Bollywood and Hollywood torrent files
17. Torrends
Torrends is a torrent search engine that directs you to torrent sites with a large Bollywood library.
18. TorrentBox.Sx
TorrentBox is a mobile-optimized torrent site with the latest collections of Bollywood movie torrents.
19. LimeTorrents
LimeTorrents has a massive collection of old and new Hindi movie torrents
20. MojBlink
MojBlink is a well-designed Indian torrent site. However, you must register before gaining access to its massive Bollywood library.
21. Bittorrent
Bittorent is a gaming torrent site with an amazing collection of Bollywood content, including movies, music, and TV shows.
22. Kinozal
Kinozal is a Hindi torrent site with content predominantly from India. However, you have to register as a forum member to get access.
23. Speedtorrent
Speedtorrent is a German torrent site rich in diverse content, including Bollywood movie torrents.
24. RARGB
RARGB’s user-friendly interface and a vast Bollywood torrent repository
25. MySpleen
MySpleen is a private torrent tracker with great Bollywood content from the 80s and 90s, as well as recent movies and other categories of torrent files.
26. Bluetopia
Bluetopia is a torrent site with a rich graphic interface. The site boasts of great Bollywood content. However, you must join its active community before gaining access to its vast torrent repositories.
27. BitLord
BitLord is a torrenting site with a feature-rich interface. The site features Bollywood movie torrent collections suitable for families and encourages all users to report adult content found on the site.
28. TopNow
TopNow is a torrent site with one of the most attractive interfaces and a well-categorized movie collection that includes Bollywood Action, Drama, Horror, Comedy, etc.
29. The Pirate Bay
Pirate Bay is home to a diverse range of torrents. The torrent king has a large repository of old and new Bollywood movies torrent files.
30. Broadcasthe.Net
BTN is a torrent site with one of the largest collections of Hollywood and Bollywood movie files as well as vast repositories of torrent file categories.
What Are The Best Torrent Sites For English Movies?
Here are the best torrent websites for English movies:
1. Zoogle
Zoogle is a torrent website not popular with torrent seekers. For this reason, this torrent site has managed to stay low under the watchful eyes of the law.
Not to judge a book by its cover, the Zoogle site boasts of more than 4 million collections of torrents in several categories, including ebooks, music, apps, etc. aside from fantastic English movie collections. If you’re a lover of TV shows, the Zoogle torrent site can help you find tons of popular TV shows as well as movies using direct download combined with magnet links, hence the name ‘zoogle.’
2. TorLock
TorLock is a nine-year torrenting site committed to safe torrenting. The site has an intuitive and navigatable user interface along with several categories of ebooks, animes, TV shows, and movies.
TorLock is one of the best torrent download sites for its direct download feature and its latest collections of movies and TV shows and its fight against fake torrents. Hence, Torlock once offered seekers $1 for every phony torrent file found on their site.
3. Torrentz2
Torrentz2 is a replacement torrent site for Torrentz.eu, which closed in 2016. Torrentz2 does not have any torrent files in its collection; instead, it serves as a torrent search engine for finding a fantastic selection of movies, TV shows, and music. Hence, you will discover torrentz2 as a fantastic site with indexes of several torrenting sites and a similar interface with its predecessor.
FitGirl Repacks has a large repository of highly compressed games for faster downloads.
2. PirateBay
This king of torrent sites has an impressive collection of game torrents in its gaming categories.
3. 1337X
1337X is one of the safest game torrent hubs where you can download the recent game torrents.
4. GazelleGames
GazelleGames is an awesome torrent site dedicated to game torrents. However, access is by invitation from members only.
5. RARBG
RARBG is one of the most reliable sources of game torrent sites, with a rich collection of game torrents in its games library.
6. Crotorrents
This is a favorite torrent site for PC gamers. Users can search games based on genre or even request a game torrent.
7. GamesTorrent
GamesTorrent is a Spanish game torrent site with a vast collection of game torrents.
8. LimeTorrents
LimeTorrents’ clean user interface and high seed/leech ratio makes it one of the best game torrent hubs for new releases.
9. Zoogle
Zoogle has over 150 game torrent collections in its game library, making it a reliable game torrent site for old and new games.
10. Skidrow Codex Games
This is a popular game torrent site for PC and mobile gamers alike.
11. TorrentGames
This is a torrent site dedicated to old and new game torrents.
12. Download Games Torrent
This is an alternative torrent site to TorrentsGames, where you can download new game torrents.
13. Kick Ass Torrents
This is one of the old game torrent sites where you can download old and new game torrent files that cut across several game genres.
14. TorrentsBees
This is a Multilanguage game torrent site with a well-organized user interface.
15. TorLock
TorLock is a popular game torrent site with tons of recent game torrent collections.
16. Torrentz2
Torrentz2 is a torrent search engine you can use to search for torrent sites with the latest collection of game torrents.
17. Pirateiro
Pirateiro has a well-indexed game torrent collection that includes a brief summary of each game title.
18. TorrentLeech
Game torrents on this site are available to new users who only get an invite from TorrentLeech members.
19. RG Mechanics
You can find hundreds of repacked game torrent files that are well-compressed to reduce file sizes.
20. ISOHunt
ISOHunt is an easily navigable torrent site with a vast collection of PC game torrents.
21. TorrentGalaxy
TorrentGalaxy is a torrent site where you can get the latest collection of game torrents
22. Torrends
Torrends helps you to find any game torrent file. The site is a torrent search engine with over 600 indexed torrent sites.
23. SteamUnlocked
This is a game-only torrent site where you can download preinstalled PC game files.
24. GloTorrents
GloTorrents is one of the few torrent sites where you can download verified game files suitable for all age categories.
25. Extratorrent
ExtraTorrent has over 200,000 game files which include old and recent game files in its game library.
26. TorrentFunk
TorrentFunk has over a million verified game files in its gaming library, which are identified by a tick.
27. Torrentz
Clicking on any game title on Torrentz connects you to a torrent site that holds the desired game torrent you want to download.
28. IGG Games
IGG games, like Torrentz, do not host torrent files.
29. Torrent Sites
Torrent Sites is a directory where you can find game torrent sites.
30. BTScene
BTScene holds a large collection of PC game torrent files
31. TorrentDB
You can find any Game title for PC and mobile devices on Torrent DB.
32. Gamesworld
Gamesworld is a public game torrent site for members and non-members.
33. Skidrowrepack
Skidrowrepack repacks game torrent files in compressed zip folders to conserve bandwidth and space.
34. PCTorrentGames
P-torrent is a dedicated Hindi torrent site for PC games.
35. DirtyTorrents
DirtyTorrents has an extensive library of PC games that cut across several genres and viewers’ ratings.
36. Gamers Maze
Gamers Maze is a game torrent site with an intuitive interface and well-indexed game categories that includes future games.
37. Toorgle
Toorgle is a torrent site that holds game files with micro torrent features. It also has an index of over 50 game torrent sites for recent game files.
38. Kinozal
Kinozal is a private game torrent site accessible to members only.
39. MagnetDL
MagnetDL functions as a torrent search engine. It also holds an impressive collection of game files in its game library.
40. Bittorrent
Bittorrent is a text-based torrent site with a large game library
41. Fast-torrent
Fast-torrent is a text-based torrent site with a link to a more intuitive and responsive game torrent site.
42. Era-IGR
This is a children-friendly game torrent site.
43. Torrents2Download
The dark-themed torrent site has an amazing collection of game torrents with a brief summary for each title
44. Xspeeds
Access to game torrents on this torrent site requires that you join the Xspeed forum.
45. Turktorrent
Turktorrent is a Turkish torrent site with several categories of Turkish torrents.
46. FunFile
FunFile has a massive game repository. However, you must register as a new user to gain access.
47. Ibit
Unlike other torrent sites, Ibit does not show recent file collections on its homepage, but you’re sure to find awesome game collections in its game category.
48. PolishSource
PolishSource is a private torrent site with some of the most recent game collections. However, users are expected to pay in cryptocurrency to register before accessing torrent files on the site.
49. Tokyo Toshokan
Tokyo Toshokan holds thousands of Japanese games in its gaming category.
What Are The Best Torrent Websites For TV Shows?
1. EZTV
If you’re looking for TV shows aired today, you’re sure of getting them on EZTV.
2. WatchSoMuch
As the name implies, It is a torrent site where you can ‘watch so much’ TV shows.
3. 1337X
Categories of TV shows you will find at 1337X include daily, weekly, monthly, and trending TV shows.
4. TorrentDownloads
TorrentDownloads is a generic torrent site with a good collection of TV shows sorted based on name, health, and size.
5. PirateBay
The king of torrent sites holds some of the best collections of TV shows.
6. RARBG
RARBG is a top torrent site known for having one of the most diverse collections of TV series.
7. LimeTorrent
The more than a decade-old torrent site is one of the most likely places to find any TV show
8. ExtraTorrent
ExtraTorrent still holds sway when it comes to torrenting high-quality TV shows.
9. Torrends
You’re sure of finding the best torrent sites for TV shows from Torrends’ over 600 indexes of torrent sites.
10. KickAssTorrents
Here, you will find a large library of quality and safe TV show torrents.
11. Torrentz2
Torrentz2, the successor to Torrentz, has a powerful search engine that makes getting any category of TV torrent as easy as ABC.
12. TorrentGalaxy
TGX is home to extensive categories of TV shows and other torrent categories.
13. TorLock
TorLock has a clean user interface that makes it easy to get any old or recent TV shows across all genres.
14. Pirateiro
Pirateiro is a TV torrent site with a simple and well-designed user interface.
15. YTS Torrent
YTS is home to old and recent TV shows. However, you will need an ad-blocker to prevent persistent pop-ups.
16. ISOHunt
ISOHunt is one of the best-known torrent search engines you can use to find any TV torrent.
17. YourBittorrent
YourBittorrent holds over one million torrents, thus making it a good source of TV torrents.
18. Nyaa.si
Nyaa is one of the best torrent sites for anime TV lovers.
19. TorrentFunk
TorrentFunk is one of the best torrent sites for verified TV shows.
20. SolidTorrents
SolidTorrents has popular TV titles and animes in its TV library.
21. DIVXTOTAL
DIvxtotal is a Spanish torrent site with vast libraries of popular Spanish TV shows.
22. LostFilm
If you’re a big fan of Indian TV shows, Lostfilm should be your favorite torrent site.
23. GloTorrents
Here, you will find all categories of torrents, including TV shows for all age groups.
24. AltTorrent
AltTorrent is another Spanish torrent site with loads of Spanish TV shows (Telemundo).
25. BigFanGroup
BigFanGroup is another Russian torrent site popular for its fantastic array of TV content.
26. Kinozal
Kinozal is a private torrent for amazing collections of old and recent TV shows
27. BitNova
BitNova is a Polish torrent site with a large collection of Polish TV torrents and other categories of TV torrents.
28. TV Vault
Here is a private torrent site focusing only on TV torrents.
29. Riperam
Riperam is a torrent site with awesome Hollywood and Bollywood TV torrents.
30. ImmortalSeed
Access to Immortalseed’s TV library is by registration.
31. Elite Torrents
Elite Torrents is home to several categories of old and recent Spanish and American TV shows
32. SceneTime
SceneTime is a paid torrenting site where you’re sure of getting verified and up-to-date TV torrents.
33. TurkTorrent
If you’re a lover of Turkish TV shows, you can have your fill of old and recent Turkish TV shows on Turktorrent.
34. Blutopia
Access to Blutopia’s large TV library is by registering for free on the Blutopia torrent site.
35. Cinemax
Cinemaz boasts of one of the best collections of horror movies and TV shows, although access is by membership invite or by buying a seedbox.
36. HDHome
HDHome is home to Chinese and American TV shows and animes. However, access is by invitation only.
37. Broadcasthenet
This is a torrent site with an active forum where you can discuss diverse issues, including trending TV shows.
38. Demonoid
Demonoid has a classic, text-based interface where you have to fork your way through its large collection of TV torrents using keywords.
39. HD Torrents
A membership to this community where you can access favorite TV shows is by getting an invite or buying an account.
40. RevolutionTT
Revolution TT has a strict policy of ‘One account per household.’ This can limit your chances of accessing diverse TV series.
41. TorrentLeech
TorrentLeech is a paid torrent site with diverse genres of recent TV shows.
42. MagnetDL
MagnetDL is both a torrent search engine and a tracker where you can download TV magnet links
43. Dirty Torrents
Dirty Torrents is home to TV series that cuts across ages. You will even get tons of adult TV series from this site.
44. Torrenting
Following the bunny on ‘Torrenting’ will lead you to endless collections of old and recent TV series. However, membership is by registration.
45. M-team
M-team is a torrent site with an amazing collection of Chinese TV shows.
46. Torrent9
Torrent9 is a torrentz alternative with a vast collection of French TV shows.
47. PassThePopcorn
You will need an invite from a member to get access to TV torrents on PassThePopcorn
48. HDU
HDU is an SSL-secured torrent site with regulated TV torrents.
49. HD4Fans
HD4Fans is home to categories of TV torrents, including documentaries.
50. AvistaZ
Getting a membership invite by joining Avista Z’s discord waitlist or buying a seedbox remains the only means of enjoying collections of old and recent TV shows.
What Are The Best Torrent Websites For Music?
1. SoundPark
This is a torrent site dedicated to all genres of music. You can download music albums and also streamline your search based on artists, genres, albums, etc.
2. RockBox
RockBox is dedicated to the rock music genre ranging from electronic to metal rock.
3. Mixtape Torrent
This is the best music torrent site to download old and new music remixes.
4. Katcr
Katcr is a version of Kickass torrent with a dedicated session for music torrents.
5. PirateBay
PirateBay is a well-known torrent site for music torrents across all genres.
6. 1337X
1337X displays an updated list of the most downloaded music torrents daily.
7. TorLock
Here, you will find only verified music torrents, making Torlock one of the safest torrent sites.
8. Torrentz2
Torrentz2 displays a list of old and new music, size, and upload time in its music library.
9. TokyoToshokan
You will find many Japanese music and themes in TokyoToshokan’s music library.
10. LimeTorrents
Lime Torrents displays music lists along with information like size, upload time, peers, etc.
11. TorrentDownloads
Music on TD are categorized into Rock, Country, R&B, Hip-hop, Rap, Pop, etc., for easy navigation.
12. DirtyTorrents
DirtyTorrents is home to diverse torrent categories; it has one of the largest music libraries for a generic torrent site.
13. TorrentFunk
Find all categories of verified music torrents on TorrentFunk.
14. RuTracker
Here, you will find music categories that cut across languages.
15. RARBG
This Bulgarian torrent site has great features combined with awesome collections of music
16. Music-torrent
This music torrent site lists music tracks in a grid style to make navigation easy.
17. YourBitTorrent
YourBitTorrent lists the top 100 of the most downloaded music torrents in its music category, along with music genres.
18. SeedPeer
SeedPeer is a popular torrent site with a large music library that cuts across all genres.
19. ISOHunt
ISOHunt has a large collection of Rock songs in its music library.
20. Nyaa
Nyaa has collections of music from North Korea and other Asian countries
21. Rarbgprx
This is an alternative to RARBG, where you will find awesome music collections.
22. iTorrents
iTorrents is a torrent caching site where you will find links to music torrent sites.
23. MagnetDL
MagnetDL is a torrent search engine with a large music torrent.
24. GloTorrent
Here, you will find some of the latest collections of music torrents.
25. TheHiddenBay
This is a version of the popular pirate bay. This site indexes all music alphabetically, making navigation easy.
26. Fast-torrent
This is a torrent site where you can download Indian songs that cut across all music categories.
27. Rustorka
Rustorka is a Hindi private torrent site where you have to buy an account or get an invite from a member to access its music library.
28. iBit
iBit is a text-based torrent with great collections of top 100 songs from charts and popular billboards, including the UK’s top 100 songs of the decade.
29. Bittorrent
Bittorrent holds large music collections across popular genres, including rap, hip-hop, rock, etc.
30. Metal-tracker
Metal-tracker is a music torrent tracker for lovers of heavy metal songs. Popular categories include chart-topping rock songs.
31. ilCorsaroneRo
ilCorsaroneRo has popular collections, including lady in jazz, billboard hot 100 singles, BTS, etc., in its music collections.
32. Torrents2Download
Torrents2Download has a large collection of theme songs in its music library.
33. JPOPSUKI2.0
This is a private music torrent site with access based on membership invite-only.
34. YGG
YGG holds large collections of music from Netflix’s original series and vast collections of 80’s and 90’s music.
35. MP3Juice
Search and discover popular music on MP3 juice.
36. Jamendo
Jamendo is a music torrent site with awesome collections of independent music and artists.
37. Partis
Partis is a private music torrent site with large collections of Spanish songs from all genres.
38. OpenCD
OpenCD is a private, music-based torrent site with vast collections of Chinese songs across all genres.
39. AniRena
AniReni is one of the best torrent sources of Japanese indie songs and animes.
40. LosslessClub
LosslessClub is a torrent source for high-quality, lossless Indian and Bollywood-themed music.
41. NordicBits
From the themes, you’re sure to find awesome Nordic music and other torrents on Nordicbits.
42. SceneTime
SceneTime is a private torrent site with the latest collections of chart-topping music.
43. Legit Torrents
Legit Torrents hosts music and other torrents that are legally free; hence no need to worry about piracy when torrenting music from this torrent site.
44. PandaCD
PandaCD features legally distributed music collections. The site also accepts voluntary contributions in cryptocurrencies.
45. FrostClick
FrostClick is a dedicated music torrent site featuring popular music collections from Alicia Gwynn, Paint POP, Daddy, etc.
46. BittorrentNow (APK)
BittorrentNow is a torrent site featuring music from charts and billboards.
47. Internet Archive
The Internet Archive holds live music collections and books, movies, and other legally free torrents.
48. Mojblink
Mojblink is a Croatian music torrent site with awesome Croatian song collections. However, access is strictly by membership invite.
49. BtEtree
This is a music torrent site for live concert recordings of trade-friendly artists.
50. Demonoid
Demonoid is known for its large collections of music shows and rock songs.
What Are The Best Software Torrenting Websites?
1. RARBG
RARBG has built a reputation over the years as a reliable torrenting site with a vast collection of high-quality software torrents.
2. TorrentDownloads
TorrentDownloads’ intuitive indexing makes it a popular source of good software torrents.
3. 1337X
1337X has a well-designed user interface that makes it a suitable source of software torrents for beginners.
4. Torrentz2
Torrentz2 is well known for its large movie and software repositories, making up part of its 61 million collections of torrents.
5. PirateBay
Pirate Bay remains the king of torrents; much loved for its consistent availability of software torrents and other categories of torrents.
6. YTS.AG
YTS is YIFY’s alternative, with a smaller collection of software torrents.
7. Torrends
Torrends.me clawed its way up as a popular torrent search engine and tracker for its quality collection of movies, TV shows, software, and games torrents.
8. Appz Universe
This is a private software torrent with a diverse collection of categories of software torrents.
9. TorrentDB
TorrentDB is a torrent site where you can download software torrents for Mac, Windows, iOS, Android, Linux, etc.
10. LimeTorrents
Rather than finding your torrent on this site, you will get links to several torrent sites that host your desired torrents.
11. TorrentDownloads
There’s no torrent you wouldn’t find on TorrentDownloads. Its software library includes diverse categories of apps for all OS platforms.
12. Kickass
Kickass is one of the long-standing torrent trackers that hosts a wide variety of software torrents.
13. ExtraTorrent
ExtraTorrent is an easily navigable torrent site with millions of torrent collections that include all software categories.
14. NordicBits
With this software torrenting site, you’re sure of finding any software type and other torrents.
15. SceneTime
SceneTime is a private torrent site that hosts wide categories of games, OS, and other software categories.
16. Legit Torrents
Legit Torrents hosts software torrents that are legally free; hence, no need to worry about piracy.
17. ISOHunt
ISOHunt has a large collection of software types, including antimalware, keygen, etc., in its software library.
18. Nyaa
Nyaa has collections of games, Linux, and DNA software
19. Rarbgprx
This is an alternative to RARBG, where you will find software collections that includes power, video editing, and watermark software torrents.
20. iTorrents
iTorrents is a torrent caching site where you will find links to software torrent sites.
21. MagnetDL
MagnetDL is a torrent search engine with a large collection of OS, antimalware, and image editing torrents with magnet links.
22. Glodls
Glo Torrent site. You will find some software magnets here, including the latest MS Office.
23. TheHiddenBay
This is a version of the popular pirate bay. This site indexes software alphabetically, making navigation easy.
24. TorrentLeech
TorrentLeech is a private torrent site that hosts varied collections of software torrents accessible only by membership invite.
25. IPTorrents
This is a member-only torrent site with a sizeable software library.
26. DirtyTorrents
DirtyTorrents categorizes its software collections based on the order of upload.
27. Torrent9
You will need a French translator to navigate Torrent9’s software collection.
28. Skidrow&Reloaded
Skidrow has one of the largest collections of gaming software.
29. TorrentDay
TD is an invite-only torrent site that hosts diverse software collections.
30. Kinozal
This software torrent site requires you to register to access software torrents.
31. Bittorrent
Bittorrent has software collections that include data recovery and Windows OS torrents.
32. ImmortalSeed
ImmortalSeed has high-quality software torrents accessible only by invite.
33. Torrenting
Get unlimited access to software from the bunny by signing up on Torrenting.com.
34. RustorKa
This is another Hindi-based software torrent site not accessible without registering.
35. RevolutionTT
This software torrent site only permits one account per household.
36. XSpeeds
Access varied software torrents by registering for free on the XSpeed torrent site.
37. Linkomanija
Linkomanija requires that you have an account to download software or other torrent types.
38. ToTheGlory
This site offers massive Chinese content accessible by registration.
39. HDArea
Access to software torrent on HDArea is by membership invite.
40. Partis
Partis is a Slovenian private torrent site accessible by membership invite.
41. Bitnova
Find the best collection of antimalware torrents on Bitnova.
42. P2PBG
This Bulgarian-based P2P site has every category of software torrents, including mobile OS compatible software.
43. Divxtotal
Divxtotal hosts software collections, including Daemon tools, graphics, Windows, and antivirus software torrents.
44. LinuxTracker
Find Linux-based software and OS on LinuxTracker.
45. PolishSource
Accessing software torrents on PolishSource is by payment using Bitcoin or other accepted cryptocurrencies.
46. HDSpace
Torrents on HDSpace are verified and are provided by users.
47. GazelleGames
GazelleGames is one of the largest sources of gaming apps. However, access is based on membership registration.
48. CGPeers
Membership to CGPeers’ software repository is by invite only.
49. Internet Archive
This is a non-profit archive of millions of software, ebooks, music, and other torrent types.
50. Slackware
This is a software-only torrent tracker
What Are The Best Torrent Websites For eBooks?
1. WikiBooks
WikiBooks host a massive collection of ebook torrents in English, Deutsch, Italiano, Hindi, and other languages.
2. BookYards
BookYards has over 7000 ebook torrents in Arts, sciences, technology, fiction, religion, and other categories.
3. ZLibrary
ZLibrary has a clean user interface and a massive collection of articles and ebooks.
4. MyAnonaMouse
This is one of the best torrent sites for educational audio and ebook torrents.
5. LibGen
Finding books on LibGen is easy by using filters like author, publisher, year, etc.
6. Internet Archive
This not-for-profit torrent site has over 30 million free ebooks in its ebook collection.
7. Project Gutenberg
This is one of the first ebook torrent sites with a collection of over 60000 free ebooks.
8. PirateBay
The most popular torrent site also has an interesting collection of ebooks that includes Stephen King, Raymond Candler, fantasy, etc., collections.
9. 1337X
Impressive book collections available on 1337X include fiction and DIY books.
10. Torrent Funk
Popular categories of ebooks you will find on torrent funk include ‘recently added,’ verified only,’ and ‘top torrents.’
11. PDFDrive
PDFDrive is a clean, straightforward ebook torrent site with over 78 million books in its collection.
12. EBOOKIE
Ebookie has more than 70 categories of ebooks ranging from academics to religion.
13. FreeBookSpot
FreeBookSpot has an easily navigable interface with advanced filters like author, language, title, ISBN, etc., making finding a book title easy.
14. Manybooks
Aside from its vast collections of ebooks, the site also serves as a platform for promoting new books and publishers.
15. Planet eBooks
Planet eBooks hosts tons of classic literature in several high-quality ebook formats.
16. Free-ebooks
Free-ebooks organizes its book collections into several categories and also provides a platform for authors to publish their books.
17. TorrentDownloads
TorrentDownloads has a massive collection of decent ebooks in multiple languages.
18. RuTracker
RuTracker has a massive collection of books well organized into several categories.
19. DirtyTorrents
DirtyTorrents has a torrent search engine for sourcing books from other sources without having to join a forum.
20. ExtraTorrent
ExtraTorrents has one of the largest indexes of book torrents and readily available magnet links for easy download.
21. Torrent9
Torrent9 is an ad-free torrent site with an awesome user experience. As a generic torrent site, Torrent9 has a large collection of ebook torrents in its ebook category.
22. SkyTorrents
SkyTorrents is an ebook torrent site with awesome ebook collections that are easily accessible without registering as a forum member.
23. DigiLibraries
DigiLibraries has a vast collection of ebooks that cuts across categories ranging from technology to fiction.
24. TorrentGalaxy
TorrentGalaxy is one of the most popular torrent sites where you can find thousands of ebook torrents.
25. Torrends
Torrends has an index of over 600 torrent sites, of which a sizeable number are book torrent sites.
26. LimeTorrents
LimeTorrents does not have a dedicated ebook section, but you’re bound to turn up loads of ebook torrents using its search engine.
27. ISOHunts
ISOHunts has a dedicated ebook section for diverse categories of books.
28. Zoogle
Zoogle is a torrent search engine with a clean interface and a vast library of ebooks.
29. AudioBB
This is an audiobook torrent site with collections of audio books ranging from fiction to non-fiction.
30. Rustorka
Access to Rustorka’s ebook library is by registration.
31. AudioBookBay
AudioBookBay has audiobook collections ranging from academics to thrillers.
32. iBit
iBit has an intuitive user interface and large ebook collections in its library.
33. BigFanGroup
Torrenting ebooks on this Russian Torrent site requires that you register to become a forum member.
34. Bibliotik
Bibliotik is a private ebook torrent site accessible only by membership invite
35. Bitspyder
Access to Bitspyder is by getting an invite to join its community or IRC channel.
36. ImmortalSeed
ImmortalSeed holds a large ebook repository accessible only by registration
37. Scenetime
Access to Scenetime ebook library as a first-timer requires that you have a valid email address for registration.
38. PolishSource
This is a paid polish torrent site that requires payment in cryptocurrency.
39. IPT
IPT is a private torrent site accessible by membership invite.
40. Riper
Riper is a Russian torrent site with massive ebook collections from notable authors
41. P2PBG
P2PBG is a Russian torrent with one of the largest collections of ebooks.
42. Alpharatio
Alpharatio is a private torrenting site with categories of ebook collections ranging from science and technology to non-fiction in its library.
43. Torrenting
Torrenting has large collections of ebooks in its library; however, membership is by registration.
44. Masters-TB
Here is another eBook torrenting site. Masters-TB is a private Russian torrent site with massive collections of Russian-authored books.
45. PDFBooksWorld
This is a premium source of free ebooks, including children’s, academics, fiction, and non-fiction books.
46. FeedBooks
FeedBooks is a paid collection of ebook torrents with titles including The Brain in search of itself, Comeuppance served cold, lot, etc.
47. LegitTorrents
Book collections in legit torrents include religious and bodybuilding books.
48. FreeTechBooks
Books available on FreeTechBook are tech-based, with a brief description to give you an idea of what you’re downloading.
What Are The Best Torrent Websites For Anime Torrenting?
1. Tokyo Toshokan
Tokyo Toshokan is a Japanese torrenting site with the best Japanese anime collections.
2. P2PBG
P2pBG brings innovation and fun to torrenting. Aside from downloading recent anime torrents, it has an active community of users participating in fun activities online.
3. SubsPlease
Subsplease is an anime torrent site for downloading new anime torrents.
4. Anidex
Anidex is an anime-based torrent with magnet links to diverse anime collections.
5. Anirena
Anirena is home to some of the best Japanese and Chinese anime torrent files.
6. AnimeTosho
AnimeTosho has the most active anime forum where torrent users discuss all anime-related topics.
7. Anie Ultime
Anime Ultime is a French anime torrent site designed by anime lovers; hence the site has a very active user community.
8. BakaBT
BakaBT is a private anime torrent site accessible only by membership invite.
9. Anime Layer
Anime Layer is a Russian anime torrent site with a beautifully designed user interface.
10. Anime Torrents
Anime Torrents is a private anime torrent site for anime movies, tv-series, Hentai, Manga, LightNovels, etc.
11. Shana Project
Shana Project is an anime torrent site that can automate anime downloads. Once activated, a new anime release will automatically download to your PC.
12. 1337X
1337X is home to HD anime magnet links. It is one of the most popular torrent sites for anime torrents.
13. The Pirate Bay
The Pirate Bay is one of the best torrent sites for diverse anime collections.
14. LimeTorrents
LimeTorrents is one of the best sources of verified anime torrents.
15. AcgnxTorrent
AccgnxTorrents updates its anime collections hourly, making it one of the torrent sites with the latest collection of anime torrents.
16. Erai-raws
Erai-raws is a black-themed anime torrent site developed by two volunteers.
17. BTDigg
BTDigg is a torrent search engine for searching any anime torrent online.
18. AnimeBytes
AnimeBytes is a private anime torrent site popularly recommended on Reddit and in anime-based communities.
19. GGBases
GGBases is a Japanese anime torrent site with broad categories of Japanese anime torrents.
20. SolidTorrents
SolidTorrents is a torrent site with a clean interface and a search engine for finding any type of anime torrents.
21. iDope
iDope is a torrent site with magnet links that makes torrenting anime easy. However, this site is accessible to users in the UK, Australia, Denmark, and India using a VPN.
22. TorrentGalaxy
TorrentGalaxy is a multipurpose torrenting site with a vast repository of animes, movies, music, games, software, and ebook content.
23. DirtyTorrents
DirtyTorrents is a torrent search engine that features the most popularly downloaded movies and TV shows in the last 24 hours.
24. YourBittorent
YourBittorrent has a rich repository of verified and unverified anime torrents.
25. ExtraTorrent
ExtraTorrent.it is the replacement site for EXtraTorrent.cc. It has one of the biggest anime collections in several categories.
26. GloTorrents
GloTorrents is a favorite torrent site that displays magnet links to awesome anime collections and additional details, including file size, seeders, leechers, and link health.
27. Demonoid
Navigating Demonoid may not be that easy due to the cluttered interface, but it has a rich repository of Japanese anime.
28. Torrent9
Torrent9 is a French torrenting site for French lovers. It has fantastic French anime titles.
29. MagnetDL
MagnetDL has a clean interface with well-arranged title bars and a prominently placed search engine for locating torrent files without the stress of rummaging through tons of anime torrent sites.
30. Torrentz2
Torrentz2 has a huge library of old and new anime torrent files from diverse sources.
31. EZTV
EZTV is the oldest and most functional torrent site where you can find good TV and anime content dating way back to the 90s.
32. IPTorrents
IPTorrents is a private torrent site accessible after making donations. It has an active forum and an extensive anime collection.
33. Torrend.to
Torrend.to features a list of over 600 torrent sites arranged in categories; hence you can easily find the best torrent site for anime using this great torrent search engine.
34. TorrentSeeker
TorrentSeeker is a torrent search engine that indexes anime search result according to popularity, niches, and languages.
35. ISOHunt
ISOHunt has a user friendly interface that makes navigating its anime torrent collection easy.
36. BitLord
BitLord is a torrenting site with a feature-rich interface. The site features anime collections suitable for families, and it encourages all users to report adult torrent files seeded on the site.
37. BittorentAM
BittorrentAM has vast repositories of torrents that cut across several categories, including animes, movies, and TV shows.
38. Bit Torrent Scene
Bit Torrent Scene is one of the best torrent sites with large repositories of anime collections. The site has several mirror URLs and IPs, making it a difficult torrent site to ban.
39. DivxTotal
DivxTotal is a torrenting site with one of the largest collections of High-Density Spanish anime.
40. NoNameClub
This is a Russian torrent site with a vast collection of movies. It also features a forum where members can discuss topics beyond torrenting.
What Are The Best Torrent Websites For Documentary?
1. 1337X
Popular documentary titles on 1337X include ‘The Godfather Family,’ Verso,’ Piazza Vittorio,’ etc.
2. TorrentDownloads
TorrentDownloads is a generic torrent site with a good collection of Documentaries and TV shows.
3. PirateBay
The king of torrent sites holds some of the best collections of epic documentaries.
4. RARBG
RARBG is a top torrent site with one of the most diverse documentary collections.
5. LimeTorrents
The more than a decade-old torrent site is home to some of the best war documentaries.
6. Torrends
You’re sure of finding the best torrent sites for documentaries from Torrends’ over 600 indexes of torrent sites.
7. Kickasstorrents
Here, you will find a large library of quality and safe documentary torrent titles.
8. Torrentz2
Torrentz2, the successor to Torrentz, has a powerful search engine that makes it easy to find documentary torrents.
9. TorrentGalaxy
Although TGX is ad-infested, it has the largest collection of documentary torrents.
10. YTS Torrent
YTS is home to the latest documentary movie titles.
11. YourBittorrent
YourBittorrent holds over one million torrents, thus making it a good source of documentaries. Popular documentary titles include the last battle, 2000 mules, Adolf Hitler, etc.
12. Nyaa.si
Nyaa is one of the best torrent sites for Japanese documentaries.
13. TorrentFunk
TorrentFunk is one of the best torrent sites for verified History, war, and nature documentaries.
14. SolidTorrents
Solid torrents have popular collections of documentary magnets.
15. DIVXTOTAL
Aside from being a Spanish TV torrent site, DIVXTOTAL also holds a decent collection of documentary torrents.
16. GloTorrents
Here, you will find all categories of torrent magnets, including recent documentaries.
17. BigFanGroup
BigFanGroup is another private Russian torrent site with fantastic collections of Russian documentaries.
18. Kinozal
Kinozal is a private torrent with a large repository of documentary torrents.
19. BitNova
BitNova is a torrent site with a large collection of polish documentaries.
20. Internet Archive
This not-for-profit torrent site with diverse documentary movie and TV collections.
21. PolishSource
Accessing documentary torrents on PolishSource is by payment using Bitcoin or other accepted cryptocurrencies.
22. Demonoid
Navigating Demonoid may not be that easy due to the cluttered interface, but using its search filter to search documentary torrents is the best way of finding documentary titles on Demonoid.
23. MagnetDL
MagnetDL is a text-based torrent site with a large collection of documentary magnets.
24. SceneTime
SceneTime is a private torrent site with the latest collection of documentary torrents.
25. Legit Torrents
Legit Torrents is a legal and verified source of free documentary torrents.
26. Bittorrent
Bittorent has one of the largest health and sports documentary collections.
What Are The Best Sports Torrent Websites?
1. Sports Video
Sports Video is a sports torrent site with access to popular sports categories, including football, wrestling, tennis, rugby, racing, etc.
2. RacingForMe
RacingForMe is a private sports torrent site for motor sports torrents.
3. MMA tracker
MMA tracker is a private torrent site for mixed martial arts sports.
4. XtremeWrestling Torrents
XWT is a wrestling torrent site accessible only by invitation.
5. T3nnis
T3nnis is the best torrent site for accessing royalty-free tennis matches. However, access is by invitation.
6. TC-Boxing
TC-Boxing is a private boxing torrent site with tons of amateur and professional high-definition boxing torrents.
7. Cycling Torrents
CT is a cycle-only torrent site with one of the largest cycling and bike racing torrents collections.
8. Racing4Everyone
R4E has tons of racing torrents, including Dakar, Dirty Mudder, F1, etc., in its collection.
9. Aussierul
Australian Football Tracker is home to a vast collection of Australian, American football, and rugby from the 70’s to 2020.
10. WorldBoxingVideoArchive
WBVA has one of the largest archives of boxing and wrestling matches.
What Are The Best Torrent Search Engines?
1. Torrends
Torrends is a popular torrent search engine powered by Google search.
2. TorrentSeeker
TorrentSeeker is a powerful search engine that combines search results from several torrent repositories.
3. iDope
iDope conducts exact, full, and multi-torrent searches from torrent sites with the highest number of seeders and peers using keywords.
4. AIO Search
AIO Search is one of the fastest torrent search engines with an indexed list of popular torrent sites and search engines.
5. Torrentz2
Torrentz2 is a powerful torrent search engine that has indexed millions of torrent sites.
6. SolidTorrents
SolidTorrents has over 30 million indexes of torrent sites; it is also home to several categories of torrent files.
7. BTDigg
BTDigg is a torrent aggregator for easy torrent download.
8. TorrentZeta
TorrentZeta has an ad-free homepage and an index of popular torrent sites.
9. AcademicTorrents
AcademicTorrents is the best torrent search engine used by researchers to find legal academic torrents.
10. Snowfl
Snowfl has an easily navigable interface but with no auto-correct feature.
11. XTORX
XTORX is a powerful, filterless torrent search engine with a simplified user interface.
12. Veoble
Veoble displays image and torrent search results in a similar style to Google.
13. TorrentProject
TorrentProject draws its results from indexes of the most popularly used torrent sites.
14. BitCQ
BitCQ is a torrent search engine best for searching Japanese torrents across several categories.
15. TorrentHounds
TorrentHounds is best for free torrent search across popular categories, including music, movies, books, and software.
Can You Get In Trouble For Torrenting?
No, you wouldn’t get into trouble for torrenting legal content. However, you can get into trouble torrenting copyrighted content online. Hence, torrenting can be legal or illegal, depending on the material you’re downloading.
Aside from getting into trouble downloading illegal content, torrenting over an unsecured connection or without using a VPN can get you into trouble by leaving your IP address, location, and other info about you exposed.
Therefore, you should use a VPN to avoid getting into trouble torrenting online.
Which Torrenting Client Is The Fastest?
UTorrent by BitTorrent is the fastest torrenting client; it is about 2MB in size and takes up minimal system resources. Also, it has a low CPU usage and is compatible with Windows, Mac, and Linux OS.
With UTorrent, you can automate your torrent download and also download directly to your mobile devices.
Are Torrenting Sites Safe?
Torrent sites are not safe; they are usually targeted by hackers and advertising companies who inject malware and adware into torrent files; hence the need to stay safe, anonymous, and protected on torrent sites by using a premium antivirus and VPN service that offers robust encryption protocols to protect your data and also make you an anonymous user, and a high-speed VPN protocol for seamless data transmission.
Can You Go To Jail For Torrenting?
You can go to jail for downloading copyrighted content intentionally or unintentionally. Torrenting is banned in several countries due to its use for illegal activities such as torrenting copyrighted materials; hence, the penalty can range from a few days in jail term to several years in jail. However, using a VPN for torrenting activities will prevent you from going to jail by making you an anonymous user with an untraceable IP address and location.
How Can I Unblock Torrent Sites From My Location?
If torrent sites are blocked in your country or region, you should use a VPN to unblock torrent sites in your location. A VPN routes your data traffic through one or more network layers, bypassing your ISP provider.
To use a VPN, you should subscribe to a premium VPN service, after which you will ensure that your VPN remains connected while you’re browsing on torrent sites. For countries where both VPN and torrents are banned, you should use a VPN service provider with obfuscation technology to bypass any firewalls against VPN connections.
How to Download Torrent Files Online
You can quickly download torrent files by using two methods.
Method 1
Follow the steps below to learn how to download torrent files
Download and install a popular torrent client. Common examples of torrent clients include BitTorrent, Utorrent, and Vuze.
Visit any of the above-listed torrent sites
Search for your desired movie or TV shows
Click on the desired movie link
Copy the movie link
Launch the downloaded torrent client
Click on the link icon and paste the download link
Click ‘OK’ to begin download
Right-click on the downloaded movie and select ‘Remove’ to prevent it from seeding.
Go to your video folder and view the downloaded movie with any video viewer of your choice. VLC will be a preferable option.
Method 2
Some torrent sites offer you a variety of download options, including ‘Magnet download’ and ‘Torrent download.’
For magnet download:
Click on the ‘Magnet download’ link
Select the installed torrent client to load the tracker from the site
Click ‘OK’ for an automatic download process
For Torrent download:
Select the ‘Torrent download’ option
Choose a preferred download mirror
Select the downloaded torrent client to open the torrent tracker from the dialogue box.
Click ‘OK’ to automatically launch the torrent client.
Safety Tips for Downloading Torrent Files
Install a reliable antivirus to protect you from malicious torrent files download only torrents with lots of seeders. Torrent files with lots of seeders, in most cases, indicate a virus-free torrent file.
Read comments and reviews about a torrent file before downloading.
Avoid downloading torrent files/trackers with .exe or .bat extension because they are malicious torrent files. A relatively safe torrent file should have a .torrent extension.
Be a part of a private torrent community. Joining a private community means that you get more trustworthy torrent files.
Understand the nitty-gritty of torrenting
Install PeerBlock to block out the IP address of known torrent trackers to prevent you from being caught.
Use a VPN to protect your IP address and location from exposure to torrent trackers.
Yes, you should use a VPN to download torrents for the following reasons.
Torrenting is not an illegal activity, but torrenting copyrighted materials is an illegal activity that can get you varying degrees of sanctions from the government/law enforcement agents. Hence, the need for a VPN to protect your IP address and location from being tracked by law enforcers or copyright trolls.
Several countries block torrent sites. If you live in a country that is not torrent-friendly, you can only access blocked torrent sites by using a VPN service. With a VPN you can bypass any restrictions placed on torrent sites to download your desired torrent files
A VPN hides your torrenting activities by making your data untraceable. You also enjoy a high level of privacy because a VPN does masks your real IP address and location. Hence, you can stay safe from hackers and malware.
EDITOR’S NOTE: Neither we nor any of the VPN services mentioned in this post support illegal torrenting. Also, Torrents should be used only for legal file sharing and downloading.
A Final Word On The Best Torrent Websites
There are many great torrent sites you can download fantastic content from. However, you need a good antivirus program and a VPN to protect you from malicious torrent files, torrent trackers or copyright trolls, and hackers who want to steal your information.
Although torrenting newly released movies and TV shows is an illegal activity, it, however, remains one of the best sources for such films and TV shows. Hence, to keep out of copyright troubles, it is mandatory to use a VPN when downloading torrent files.
In conclusion, any of the best torrent websites we mentioned above are ideal for movie downloads. You can use any of the Bollywood torrenting sites, Hollywood torrenting site, and more.
However, we do recommend that you make use of a strong antivirus program to scan the downloaded torrent files on your PC.
Today, we will answer the question – when is hacking illegal and legal?
Before we jump into the topic of when hacking is considered illegal and when it is considered legal, let’s try to understand what hacking is.
What Is Hacking?
There are several ways to explain the process of hacking. It could be described as a breach of the system or unauthorized access.
Still, hacking is an unwarranted attempt to infiltrate a computer or any other electronic system to attain information about something or someone.
Whenever we hear or read about someone’s computer or network being hacked, we instantly picture an individual sitting in a dark room full of tangled wires, computer screens, and multiple keyboards, rapidly typing a programming language on one of the computer screens.
While hacking is portrayed as quite intriguing in movies, it is entirely different. Websites like SecureBlitz and other cybersecurity blogs can educate you on the measures you should take if your device is hacked.
The hacking scenes in movies and TV shows are full of action, suspense, and drama, making them enjoyable and entertaining.
But in reality, hacking is quite dull. The hacker types a series of commands, instructing the computer system via a programming language like Python, Perl, or LISP, and waits for the results, which may take hours. However, the computer performs the actual hacking tasks.
Along with being tedious and time-consuming, piracy is also complicated and sometimes dangerous.
Hackers use many different types of tools to hack into a software system. A few of these tools are:
Sn1per is a vulnerability scanner used by hackers to detect weak spots in a system or network.
John The Ripper (JTR) – This is a favorite tool amongst hackers. It is used for cracking even the most complicated passwords as a dictionary attack. A dictionary attack is a form of brute-force attack where the hacker enters numerous passwords, hoping to guess the correct one.
Metasploit – This is a Penetration Testing Software. It is a hacking framework used to deploy payloads into vulnerabilities. It provides information about software weaknesses.
Wireshark is a network traffic analyzer used for troubleshooting and analyzing network traffic.
There Are Three Types Of Hackers –
The Black Hat Hackers,
The White Hat Hackers and
The Grey Hat Hackers.
The difference between each will be discussed below.
1. Black hat hackers
Black Hat hackers are cybercriminals who illegally gain unauthorized or illegal access to individual or group computers (devices and networks) to steal personal and financial information like names, addresses, passwords, credit card details, etc.
A Black Hat hacker may also use malicious tools, such as viruses, Trojans, worms, and ransomware, to steal or destroy files and folders, and take control of a computer or network of computers, demanding money for release.
In essence, Black Hat hackers can work alone as individuals or belong to organized crime organizations as partners or employees, and are responsible for more than 2,244 daily computer breaches.
2. White Hat Hackers
White-hat hackers, also known as ethical hackers, are computer security professionals who utilize their hacking knowledge to protect the computer networks of businesses and organizations.
They aim to detect and reinforce security loopholes, weaknesses, or flaws in systems and networks that cybercriminals can explore.
For this reason, White hat hackers think and act like black hat hackers and also use a whole lot of testing tools and techniques deployed by black hat hackers in exploiting systems and network weaknesses.
Some of the best white-hat hackers were previously black-hat hackers who, for various reasons, have decided to use their hacking knowledge and skills to fight against cybercrimes.
3. Grey Hat Hackers
Grey hat hackers fall in between the divide; they are neither black hat nor white hat hackers, but their activities are termed ‘illegal.’
This is because they gain unauthorized access to individual or group networks to steal data and identify security flaws or loopholes in systems, networks, or programs.
Unlike black-hat hackers, grey-hat hackers do not seek to make immediate money or benefit from their activities.
Grey hat hackers can be beginner hackers who hack into systems and networks to test and develop their hacking skills before deciding which side of the divide to join.
However, most Grey hat hackers are lone-range hackers who work as bug bounty hunters, finding and reporting security flaws in corporate networks or extracting and exposing confidential information for all to see, as in the case of WikiLeaks, which represents the most significant information leak.
Best Antivirus With Ironclad Protection Against Hackers
Surfshark Antivirus
A 360-degree solution for all threat categories.
A 360-degree solution for all threat categories. Show Less
Heimdal Security
Heimdal Security protects its users from advanced malware attacks by making use of next-generation technology. Your best...Show More
Heimdal Security protects its users from advanced malware attacks by making use of next-generation technology. Your best intelligent threat prevention tool. Show Less
Malwarebytes
Your everyday protection against malware like ransomware, spyware, viruses, and more.
Your everyday protection against malware like ransomware, spyware, viruses, and more. Show Less
Norton Antivirus Plus
Your award-winning cybersecurity solution for complete device protection.
Your award-winning cybersecurity solution for complete device protection. Show Less
Trend Micro Maximum Security
Maximum security for households and office use.
Maximum security for households and office use. Show Less
When Is Hacking Illegal And Legal?
Hacking has always been portrayed as a felony, an unauthorized entry into a network. However, it began when MIT introduced the first computer hackers, whose job was to modify software to improve its performance and efficiency. However, some people started using this software for felonious activities.
Hacking is gaining unauthorized access to a computer system or network. It can be used for various purposes, including stealing data, installing malware, or disrupting operations. Hacking can be illegal or legal, depending on the circumstances.
Legal Hacking
There are several situations in which hacking is legal. For example, security researchers may hack into a system to test its security or to find vulnerabilities. Law enforcement officials may also fall into a system to investigate a crime. In these cases, hacking is done with the system owner’s permission or with a court warrant.
Illegal Hacking
Hacking is illegal when it is done without permission from the system owner. This includes hacking into a system to steal data, install malware, or disrupt operations. Illegal hacking can also involve gaining unauthorized access to a system to obtain information that is not publicly available.
Determining Whether Hacking Is Legal
The legality of hacking can be a complex issue. Several factors are considered by courts when determining whether hacking is legal, including the hacker’s intent, the method used to gain access, and the resulting damage.
In general, hacking is considered illegal if it is done without permission from the system owner and if it causes damage to the system or its users.
However, there are some exceptions to this rule. For example, hacking may be legal if it is done with the system owner’s permission or if it is done to test security or investigate a crime.
Here is a table summarizing the legality of hacking:
Type of Hacking
Legality
Examples
Legal Hacking
With permission from the system owner or with a warrant from a court.
Security researchers hack into a system to test its security. Law enforcement officials hack into a system to investigate a crime. System administrators use hacking techniques to troubleshoot a problem within a system.
Illegal Hacking
Without permission from the system owner.
Hackers gain unauthorized access to a system to steal data. Hackers install malware on a system. Hackers disrupt the operations of a system.
The answer to the question – when is hacking illegal? – is simple! When a hacker tries to breach a system without authorization, it is considered unlawful. These kinds of hackers are called Black Hat Hackers.
They are the type of hackers known for their malicious and notorious hacking activities. Initially, hackers used to hack systems to demonstrate their ability to breach them. They used to cut just for fun.
Then, a hack is used to expose someone or leak information. For example, a group of hackers called themselves “Anonymous,” who claimed to have personal information about Donald Trump and were threatening to expose them. They are also threatening to reveal the “crimes” committed by the Minneapolis Police Department (MPD) following the murder of George Floyd.
Another example is when thousands of messages from hacked emails were leaked from Clinton campaign chairman John Podesta’s Gmail account. The list goes on and on, as hackers don’t cut to prove a point or to expose someone. They hack for political reasons, for money, or are driven by some purpose or motive.
These actions are deemed illegal and felonious under the Computer Misuse Act (1990) and other legislative acts such as the Data Protection Act (2018) and the Cybercrime Prevention Act of 2012.
Legal hacking refers to a situation where a hacker is granted permission to access a system or network. This type of hacking is also known as Ethical Hacking.
In a technological era, it has become easier for radical organizations to finance hackers to infiltrate security systems. This has led to a steady increase in cybercrime.
It has become imperative, now more than ever, for companies and governments to legally hack into their operations to discover and fix vulnerabilities and prevent malicious and unlawful hacking from compromising the safety of classified information. This type of hacking is typically performed by either White Hat Hackers or Grey Hat Hackers.
The White Hat Hackers are those hackers who look for backdoors in software when they are legally permitted to do so.
The Grey Hat Hackers are those hackers who are like Black Hat hackers, but do not hack to cause any damage to any organization or people’s personal information or data. Companies or organizations hire them to hack into their computer systems and notify the administration if any vulnerabilities are found. This is done so that these organizations can further secure their networks.
Software companies utilize such hackers and hacking processes.
There are many types of ethical hacking. A few of them are
Disclosing findings to the owner, seeking remediation
Concealing activities, benefitting from stolen information
Examples
Penetration testing, bug bounty programs, security research
Data breaches, identity theft, ransomware attacks
Laws
It may be governed by specific industry regulations (e.g., HIPAA)
Computer Fraud and Abuse Act (CFAA), Digital Millennium Copyright Act (DMCA)
Penalties
May vary depending on the severity of the offense, civil lawsuits
Fines, imprisonment, probation
Types Of Legal Hacking
Penetration testing is a security assessment that simulates an attack on a computer system or network to evaluate its security. The goal of penetration testing is to identify and exploit vulnerabilities in the system so that they can be fixed before malicious actors use them.
Penetration testing can be done in several ways, but it is typically divided into three types:
1. White box testing
White box testing is the most comprehensive penetration testing because the tester has complete information about the system. This allows the tester to simulate a realistic attack and identify the most severe vulnerabilities. However, white box testing can also be the most expensive type of penetration testing because it requires the tester to have a deep understanding of the system.
2. Black box testing
Black box testing is the least comprehensive type of penetration testing because the tester has no prior knowledge of the system. This type of testing is often used to identify vulnerabilities that inexperienced attackers are likely to exploit. However, black box testing can also be the least effective type of penetration testing, as it may not identify the most severe vulnerabilities.
3. Gray box testing
Gray box testing is a combination of white box and black box testing. The tester has limited information about the system, but they have more information than in a black box test.
This type of testing is often used to identify vulnerabilities that attackers with some experience would exploit. Gray box testing is often seen as a good compromise between the comprehensiveness of white box testing and the cost-effectiveness of black box testing.
Types Of Illegal Hacking
Black hat or illegal hackers gain unauthorized access to computers and networks to steal sensitive data and information, hold computers hostage, destroy files, or blackmail their victims using various tools and techniques, not limited to the standard types listed below.
1. Phishing
Phishing techniques trick unsuspecting victims into believing they are interacting with legitimate companies or organizations. It usually comes in the form of email or SMS messages, where victims are convinced to click on a link or download malicious file attachments.
2. Ransomware
Black hat hackers take computer hostages by blocking legal access and demanding ransom from the victims before unblocking access to their computers.
3. Keylogger
Keyloggers are used to log and collect information from unsuspecting victims by remotely recording and transmitting every keystroke they make on their devices, often through the use of keyloggers or spyware.
4. Fake WAP
Hackers use fake Wireless Access Point software to trick their victims into believing they are connecting to a wireless network.
5. Bait and switch
The hacker tricks unsuspecting victims into believing they are clicking on advertisements by purchasing a web space and placing malicious links that download malware to the victims’ computers when they are connected.
Here is a table summarizing the types of illegal hacking:
Type of Hacking
Description
Examples
Phishing
A type of social engineering attack that uses fraudulent emails or text messages to trick victims into clicking on a malicious link or downloading a malicious file.
An email that appears to be from a legitimate bank but is actually from a hacker may request that you click on a link to update your account information.
Ransomware
A type of malware that encrypts a victim’s files and demands a ransom payment to decrypt them.
A hacker may infect your computer with ransomware and then demand a payment of $1,000 to decrypt your files.
Keylogger
A type of software that records every keystroke you make on your keyboard.
A keylogger can be installed on your computer without your knowledge and then used to steal your passwords, credit card numbers, and other sensitive information.
Fake WAP
A fake wireless access point that is configured to appear as a legitimate wireless network.
A hacker may set up a fake WAP in a public place and then use it to steal the login credentials of unsuspecting victims who connect to it.
Bait and switch
It is an attack that tricks victims into clicking on a malicious link by disguising it as an advertisement.
A hacker may purchase a web space and then place a malicious link that appears to be an advertisement for a legitimate product or service. When a victim clicks on the link, they are taken to a malicious website that downloads malware to their computer.
Commonly Used Hacking Techniques
Here are the most common hacking techniques used by hackers:
SQL Injection Attack – SQL stands for Structured Query Language. It is a programming language originally invented to manipulate and manage data in software or databases.
Distributed Denial-of-Service (DDoS) – This technique targets websites to flood them with more traffic than the server can handle.
A keylogger is software that documents the key sequence in a log file on a computer that may contain personal email IDs and passwords. The hacker targets this log to get access to such personal information. That is why the banks allow their customers to use their virtual keyboards.
Yes, hacking is a crime in the United States. Accessing individual PCs and networks without authorization or using illegal means is prohibited by the Computer Fraud and Abuse Act (CFAA). This act makes it unlawful to access someone else’s computer or network without their permission.
Hacking can be accomplished in various ways. It could involve using malicious software, such as viruses or spyware, to access a system or network. It could also include exploiting security flaws or vulnerabilities in the system.
Additionally, it may involve stealing passwords or other login credentials to gain unauthorized access to a system or network.
Since you get the answer to the question – when is hacking illegal? You could face prosecution and severe penalties if caught hacking in the U.S. This could include fines, jail time, and a permanent criminal record.
So, if you’re considering hacking into someone’s system or network, think twice before doing so. It could have severe consequences for you and your future.
Why Is Hacking Considered A Crime?
Hacking is considered a crime if you:
Delete or damage data from the computers of individuals or organizations
You send or aid in sending spam messages
Buy or sell passwords or licenses that can be used to illegally access computers or programs for the purpose of impersonation.
You access data or information from devices and networks without due permission.
You defraud victims using computer and ICT skills.
Access national security information from a government website or networks
Extort computer users
And so much more.
How To Prevent Hackers
Take the following steps to protect yourself from falling victim to black hat hackers
Connecting only to secured WiFi networks. If you have to connect to a public WiFi network, do so using a VPN.
Downloading files and programs from authenticated websites
Not sharing too much information about yourself on social media platforms
Avoiding file-sharing services, including torrenting
Shopping only on verified eCommerce websites
Best Antivirus With Ironclad Protection Against Hackers
Surfshark Antivirus
A 360-degree solution for all threat categories.
A 360-degree solution for all threat categories. Show Less
Heimdal Security
Heimdal Security protects its users from advanced malware attacks by making use of next-generation technology. Your best...Show More
Heimdal Security protects its users from advanced malware attacks by making use of next-generation technology. Your best intelligent threat prevention tool. Show Less
Malwarebytes
Your everyday protection against malware like ransomware, spyware, viruses, and more.
Your everyday protection against malware like ransomware, spyware, viruses, and more. Show Less
Norton Antivirus Plus
Your award-winning cybersecurity solution for complete device protection.
Your award-winning cybersecurity solution for complete device protection. Show Less
Trend Micro Maximum Security
Maximum security for households and office use.
Maximum security for households and office use. Show Less
Conclusion
In this post, we answered the question – when is hacking illegal? And when is hacking legal?
Also, we hope that you have learned that the white hat hackers are ‘the good guys,’ and the black hat ones are the ‘bad guys,’ and what to do to protect yourself from the bad guys online.
Now that you know when hacking is legal or illegal, you should endeavor to take the steps recommended in this article to keep your devices and networks protected from ‘the bad guys who could cost you a lot if your devices or networks eventually get compromised.
Today, we will show you how to get a cybersecurity job with no experience.
This article can help if you’re looking for a cybersecurity job without experience.
For every worker, the beginning stages are always tricky. Employers are always looking for an employee with years of experience in their given niche, and it is impossible to get job experience without employment.
This builds tensions in new job seekers, such that some get frustrated and give up the hope of ever getting a job. Nevertheless, people have been able to secure employment without experience– anyone can achieve this feat.
Cybersecurity is one hot field in today’s digital world as almost every company operating online needs a cybersecurity expert, and the pay is huge. There are many cybersecurity job opportunities available on the internet, as well.
To start with, let’s consider the tasks involved in a cybersecurity job.
What Are The Tasks Involved In A Cybersecurity Job?
There are several responsibilities usually assigned to cybersecurity personnel. The primary responsibility, however, is to protect online data. Cyber attacks are on the rise today. With the amount of personal and corporate information companies store online, it’ll be very costly if hackers and cyber thieves compromise their website or other online platforms.
A cybersecurity staff is expected to provide security for the files and company network online, monitor activities, and fix security breaches whenever they happen. It is a delicate profession, so most companies only seek to employ people with experience in the field.
For instance, you must learn all the essentials of Penetration Testing before landing a job as a Pen Tester. The cybersecurity world is vast, so one person would struggle to handle every task proficiently.
How do you get a cybersecurity job without experience? These steps will provide the answer:
1. Get a certificate
It is somewhat impossible for any employer to employ a cybersecurity staff without a certificate. Certifications carry much weight in the cybersecurity industry, just as in other IT fields. An absence of it on your CV/Resume lowers your chances of landing your dream cybersecurity job.
You won’t want to apply for a cybersecurity job if you do not have the skills. Whereas you can acquire these skills without getting a certificate, you should acquire the skills along with a certificate.
Some employers may use the certificate issuer as a referee and the stated duration of your training can be seen as job experience.
2. Highlight your skills and achievements
You’re applying for a cybersecurity job, but it may not be the only IT field where you are skilled or certified. If you’ve got certification in other IT fields, it is recommended that you highlight them in your CV or Resume.
This advantage will be more appreciative of the other skills related to cybersecurity, such as web development, and programming languages such as JavaScript, C, and C++.
Also, highlight certain IT-related activities and milestones you have achieved previously in your career. All these would indicate that you are not new to the IT industry.
3. Work On Your Personality
Sometimes, it takes more than just skills to get a job. Your personality is also essential. The way you relate to others, how you cope under certain situations, time management, confidence, humility, and other interpersonal skills will be taken into consideration by your employer.
Lousy character and behavior have made so many people lose job opportunities no matter how skilled they were. If you’re going to have a face-to-face interview, your personality may be just what will seal off your employment letter.
Being a person with a great personality shouldn’t just be written on your CV/Resume; it should reflect your behavior.
Some employers might want to sign you off as an intern for some time before they offer you the job. Think of it as a test; the possibility of getting a cybersecurity job without experience relies on how you perform as an intern.
It is an excellent opportunity, so you should take it; you can quickly get a cybersecurity intern job. It allows you to test your skills and gain some of the experience you lack. Most companies pay interns so that you won’t be working for free.
Remember, cybersecurity is a dynamic field with a growing demand for skilled professionals. By taking the initiative to learn, build your skillset, and network within the industry, you can increase your chances of landing a fulfilling cybersecurity role, even with no prior experience.
How To Get A Cybersecurity Job With No Experience: Frequently Asked Questions
Breaking into cybersecurity without prior experience can seem daunting, but it’s definitely achievable. Here are some FAQs to guide you on your journey:
Can you start a career in cybersecurity with no experience?
Absolutely! While experience is valuable, it’s not always a prerequisite for entry-level cybersecurity roles. The cybersecurity industry is constantly evolving, and employers are often willing to consider enthusiastic individuals with the right skills and willingness to learn.
Do you need IT experience to work in cybersecurity?
A basic understanding of IT concepts is helpful but not necessarily mandatory for all cybersecurity roles. However, familiarity with computer networks, operating systems, and software would definitely be a plus.
How do I start a career in cybersecurity with no experience?
Here’s a roadmap to get you started:
Build foundational knowledge: Enroll in online courses, certifications, or boot camps to gain a solid understanding of cybersecurity concepts, terminology, and threats.
Develop relevant skills: Focus on practical skills like penetration testing, security analysis, or incident response. Many online resources offer tutorials and practice exercises.
Consider Certifications: While not essential for entry-level roles, certifications like CompTIA Security+ or Network+ validate your knowledge and make you a stronger candidate.
Gain practical experience: Volunteer for cybersecurity projects, participate in bug bounty programs (where you ethically identify vulnerabilities in systems and get rewarded), or look for internship opportunities to gain hands-on experience.
Network and build your online presence: Connect with cybersecurity professionals on LinkedIn, participate in online forums and communities, and showcase your knowledge and passion for the field.
Can a non-IT person learn cybersecurity?
Absolutely! Cybersecurity encompasses a broad range of specialties. Some roles might require more technical expertise, while others focus on policy, risk management, or even legal aspects of cybersecurity. There’s a niche for individuals with diverse backgrounds and skill sets.
What is the easiest field in cybersecurity?
There’s no inherent “easiest” field. However, some entry-level roles might be less technical, focusing on security awareness training, security administration, or security analyst positions that involve monitoring systems for suspicious activity.
What is the lowest cybersecurity job?
Titles can vary, but some entry-level cybersecurity positions include Security Analyst, IT Security Specialist, Cybersecurity Analyst, or Security Operations Center (SOC) Analyst. These roles often involve monitoring systems, analyzing security data, and following established procedures to identify and address security incidents.
How do I start a cybersecurity career from scratch?
Here are steps to kickstart your journey:
Build a Foundational Knowledge
Familiarize yourself with core cybersecurity concepts like network security, system administration, and common cyber threats. Free online resources, courses, or certifications can provide a strong base.
Consider Earning Certifications
While not always mandatory, industry-recognized certifications like CompTIA Security+ validate your knowledge and enhance your resume.
Develop Practical Skills
Look for opportunities to gain hands-on experience. Participate in cybersecurity workshops, bug bounty programs (ethical hacking with permission), or contribute to open-source security projects.
Network and Build Relationships
Connect with professionals on LinkedIn, attend industry events, or join online cybersecurity communities. Networking can open doors to potential opportunities.
Is 40 too old to start a career in cybersecurity?
Absolutely not! Cybersecurity is a growing field with a high demand for skilled professionals. Your age can be an asset, as you might bring valuable experience from previous careers that can translate well into cybersecurity.
Do I need coding for cybersecurity?
While coding skills can be beneficial, they aren’t always mandatory for entry-level cybersecurity roles. However, some familiarity with scripting languages (Python, Bash) or basic programming concepts can be helpful. The specific requirements will vary depending on the role you pursue.
How difficult is cybersecurity?
Cybersecurity is a broad and evolving field. There will always be new things to learn and challenges to overcome. However, with dedication and a passion for learning, you can develop the necessary skills and knowledge to succeed.
Final Thoughts
A company’s business’s security relies on its cybersecurity staff’s shoulders. It’s a huge responsibility to understand that they always seek people with certifications and experience.
If you want a cybersecurity job, you can get it by applying the steps discussed above, whether you have experience or not.
Note: This was initially published in September 2020, but has been updated for freshness and accuracy.
Today, we will show you the list of geo-restricted streaming services in Africa, Asia, North America, Europe, and more. Also, we will show you how to unblock geo-restrictions.
Sometimes, when you try to access an online streaming service, you receive a message that says such a service is unavailable for your region.
This is simply what geo-restriction entails. The rights owner to the streaming content has made it exclusive to a particular geographical location (country or continent). Anyone outside such geographical location will be unable to access the content.
Aside from streaming services, geo-blocked websites are also available. Whatever content these websites offer – news, articles, etc. – cannot be accessed from outside regions.
What Is Geo Restricted Content?
Geo-restricted content refers to online media, websites, or services only accessible within specific geographic regions due to licensing agreements, legal restrictions, or business strategies.
For instance, streaming platforms like Netflix or Hulu may offer different shows or movies based on the user’s location.
These restrictions are enforced using technologies like IP address tracking, which identifies a user’s location and either grants or denies access to the content.
Users often bypass these restrictions with tools like VPNs to simulate being in an allowed region.
One primary reason for geo-restrictions is copyright laws. The rights owner of these services differ from region to region, and airing contents in a region without the rights would be a legal fault.
Also, the owner of a particular streaming right might offer the same services in different regions under different brands. The content provided may be personalized and made exclusive to each region.
Streaming services that focus on providing services to a specific region might also decide to restrict outsiders from gaining access.
Geo-blocking technology utilized by these streaming services can detect your location by reading your real IP address. As you connect to the internet, you do so with an IP address issued from your network provider’s proxy server.
Not that your IP tells your location literally, the technology can detect where the web request is coming from, and if the region is restricted, access will be denied.
The Big List of Geo-Restricted Streaming Services
List Of Geo-Restricted Streaming Services In Africa
Listed below are some geo-restricted streaming services in Africa.
Netflix: Netflix is a popular platform for streaming TV shows and movies. Whereas the service is available in some African countries, some video contents are geo-restricted. You can only gain access to the full Netflix library if you are in the US.
Spotify: the Spotify platform, despite its global domination in the music industry, is available in just 5 African countries. These five countries include Tunisia, Algeria, Morocco, Egypt, and South Africa. African lovers outside these countries cannot officially stream music on the platform.
HBO GO: this video streaming platform is only available in the United States. For every other region, including Africa, it is geo-blocked.
FXNOW: the FXNOW platform provides video streaming content. It is also a television channel on the Dish Network. The platform is available in just the US, so Africans can’t access it.
Amazon Prime Video: While Prime Video is available in many African countries, its library differs significantly from the US version, with many popular shows and movies missing.
Disney+: Currently available in South Africa and soon to launch in other African countries, Disney+ still has limited content accessibility compared to its US library.
Hulu: Hulu is completely unavailable in Africa, with its vast library of TV shows and movies locked out for African viewers.
HBO Max: Similar to HBO GO, HBO Max is only available in the US and inaccessible to viewers in Africa.
CBS All Access: This platform offering shows from the CBS network is geo-restricted in Africa, leaving fans without official access.
Apple Music: Apple Music offers a smaller library and limited features in some African countries compared to its global availability.
Tidal: While Tidal has expanded its reach in Africa, it remains unavailable in several countries, depriving music enthusiasts of its high-quality audio and curated content.
YouTube Music Premium: Like YouTube itself, YouTube Music Premium offers limited content in certain African regions, with some songs and music videos missing.
Deezer: Deezer’s global library is not fully accessible in all African countries, leaving some users with a restricted selection of music.
List Of Geo-Restricted Streaming Services In Europe
Here are some geo-restricted streaming services in Europe.
Crackle: Crackle is a platform for video streaming Hollywood movies. Several TV shows can also be streamed on the platform. Sony Pictures own it, and as a US-based service, it is unavailable in any European country.
Pandora: This is an online platform for streaming music and radio listening. It is a subsidiary of Sirius XM Satellite Radio. Pandora is available in about 26 regions, but none of the regions are in Europe.
Hulu: Hulu has more than 25 million users and is a platform owned by Walt Disney. On Hulu, you can watch Live TV, shows, and movies. However, its streaming content is restricted in Europe.
HBO GO: When it comes to action series and movies, HBO GO is a go-to streaming platform. The contents served on HBO GO are premium. It was recently launched in a few European countries, but a majority still cannot access it.
Peacock: This NBCUniversal streaming service featuring original shows and classic sitcoms remains unavailable across Europe.
Paramount+: The home of CBS and Paramount Pictures content, Paramount+ is currently geo-restricted in most European countries.
Sling TV: Offering affordable live TV streaming packages, Sling TV remains inaccessible to European viewers.
AT&T TV Now: This live TV streaming service with diverse channels is unavailable in Europe, leaving cord-cutters with limited options.
Discovery+: Documentaries and reality TV fans in Europe miss out on Discovery+, as the platform is currently geo-restricted in the region.
List Of Geo-Restricted Streaming Services In North America
Listed below are some geo-restricted streaming services in North America;
EuroSportPlayer: EuroSportPlayer is a European-based streaming platform for live sports, including Football, Tennis, Athletics, etc. As described, it is based in Europe, and people in North America cannot enjoy its streaming content.
Absolute Radio: One of the best platforms to stream music out there is Absolute Radio. The platform’s motto says “Where Real Music Matters” and “The home of the no-repeat guarantee” so you can understand the quality of music you’ll get. Unfortunately, it is geo-blocked in the United States and other North American countries.
Sky Go: Sky Go is an online alternative to Sky TV. Movies, series, shows, from various producers, can be enjoyed on Sky Go but, the platform is only available in Europe.
Channel 5: This is a free-to-air TV owned by ViacomCBS Networks; the platform is top-rated in the UK and Australia. Amazing contents are provided, but all are unavailable in North America.
BBC iPlayer: This UK-based platform boasts original dramas, comedies, and documentaries, but remains locked out for North American viewers.
ITV Hub: Featuring popular British shows like Downton Abbey and Line of Duty, ITV Hub is unavailable in North America due to licensing agreements.
Channel 4 On Demand: Offering a mix of British comedy, drama, and factual programs, Channel 4 On Demand remains geo-restricted in North America.
Sky Sports: This European sports giant with extensive coverage of Premier League and other leagues is unavailable to North American viewers.
Eurosport: While EurosportPlayer is restricted, the broader Eurosport platform with international sports coverage is also unavailable in North America.
Here are some geo-restricted streaming services in Asia.
Epix: The Epix Entertainment LLC owned platform is one for streaming TV shows. It is US-based, and only US residents have access to watch these shows.
NBC Sports: NBC Sports is a popular sports streaming platform. You can watch live sports games, highlights, and previews but not within the Asian region.
Max Go: MaxGo provided by Cinemax offers original movies and TV series. Cinemax made the platform only accessible from the United States.
Hulu: This massive library of TV shows and movies remains geo-blocked throughout Asia, leaving viewers without access to its popular content.
HBO Max: Similar to HBO GO, the premium content of HBO Max is unavailable in most Asian countries, excluding select markets like Hong Kong and Singapore.
Peacock: NBCUniversal’s streaming platform with original shows and classic sitcoms remains inaccessible across Asia, offering limited options for fans of its content.
Sling TV: This affordable live TV streaming service is geo-restricted in Asia, leaving viewers without a convenient cord-cutting option.
AT&T TV Now: This diverse live TV streaming service is unavailable in most Asian countries, limiting viewers’ access to its extensive channel lineup.
List Of Geo-Restricted Streaming Services In South America
Peacock: NBCUniversal’s platform with original shows and classics is locked out for South American viewers.
Paramount+: The home of CBS and Paramount Pictures content remains unavailable across most South American countries.
Sling TV: This affordable live TV streaming service is geo-restricted in South America, limiting cord-cutting options.
Discovery+: Documentaries and reality TV fans in South America miss out on Discovery+, as the platform is currently unavailable in the region.
Eurosport Player: The European sports streaming giant with extensive coverage of Premier League and other leagues is unavailable for South American viewers.
List Of Geo-Restricted Streaming Services In Australia
Hulu: This massive library of TV shows and movies remains locked out for Australian viewers.
HBO Max: The premium content of HBO Max, including original shows and blockbuster movies, is inaccessible in Australia.
Peacock: NBCUniversal’s streaming platform with original comedies and classic sitcoms is currently unavailable in Australia.
Sling TV: This affordable live TV streaming service with diverse channels remains geo-restricted in Australia.
AT&T TV Now: This comprehensive live TV streaming service offering sports, news, and entertainment is absent from the Australian market.
List Of Geo-Restricted Streaming Services In Oceania Countries
Hulu: This vast library of TV shows and movies remains locked out for Oceania viewers, offering no legal access to its popular content.
HBO Max: The premium content and original shows of HBO Max are unavailable in most of Oceania, with only limited exceptions like New Zealand.
Sling TV: This affordable live TV streaming service remains inaccessible in Oceania, leaving viewers without an alternative to traditional cable packages.
AT&T TV Now: This diverse live TV streaming service is unavailable throughout Oceania, limiting viewers’ options for cord-cutting.
Peacock: NBCUniversal’s streaming platform with original shows and classic sitcoms is completely geo-restricted in Oceania,
How To Unblock Geo-Restricted Streaming Services
No matter the region or country you reside in, you can unblock any geo-restricted streaming services using any of the following:
VPN Service
A VPN service is about your best bet if you want to unblock geo-restricted streaming services. VPNs can mask your real IP address, and as a result, your actual geographical location is hidden.
With this, you get to browse with a different IP address provided by the VPN server. The VPN Servers are located in various countries, so all you need to do is to connect with one in the country where the streaming contents are not geo-blocked.
87% OFF
PureVPN
PureVPN is one of the best VPN service providers with presence across 150 countries in the world. An industry VPN leader...Show More
PureVPN is one of the best VPN service providers with presence across 150 countries in the world. An industry VPN leader with more than 6,500 optimized VPN servers. Show Less
84% OFF
CyberGhost VPN
CyberGhost VPN is a VPN service provider with more than 9,000 VPN servers spread in over 90 countries. Complete privacy...Show More
CyberGhost VPN is a VPN service provider with more than 9,000 VPN servers spread in over 90 countries. Complete privacy protection for up to 7 devices! Show Less
67% OFF
TunnelBear VPN
TunnelBear is a VPN service provider that provides you with privacy, security, and anonymity advantages. It has VPN...Show More
TunnelBear is a VPN service provider that provides you with privacy, security, and anonymity advantages. It has VPN servers in more than 46 countries worldwide. Show Less
84% OFF
Surfshark
Surfshark is an award-winning VPN service for keeping your digital life secure. Surfshark VPN has servers located in...Show More
Surfshark is an award-winning VPN service for keeping your digital life secure. Surfshark VPN has servers located in more than 60 countries worldwide. Show Less
83% OFF
Private Internet Access
Private Internet Access uses world-class next-gen servers for a secure and reliable VPN connection, any day, anywhere.
Private Internet Access uses world-class next-gen servers for a secure and reliable VPN connection, any day, anywhere. Show Less
65% OFF
FastVPN (fka Namecheap VPN)
FastVPN (fka Namecheap VPN) is a secure, ultra-reliable VPN service solution for online anonymity. A fast and affordable...Show More
FastVPN (fka Namecheap VPN) is a secure, ultra-reliable VPN service solution for online anonymity. A fast and affordable VPN for everyone! Show Less
35% OFF
Panda Security
Panda VPN is a fast, secure VPN service facilitated by Panda Security. It has more than 1,000 servers in 20+ countries.
Panda VPN is a fast, secure VPN service facilitated by Panda Security. It has more than 1,000 servers in 20+ countries. Show Less
68% OFF
NordVPN
The best VPN service for total safety and freedom.
The best VPN service for total safety and freedom. Show Less
60% OFF
ProtonVPN
A swiss VPN service that goes the extra mile to balance speed with privacy protection.
A swiss VPN service that goes the extra mile to balance speed with privacy protection. Show Less
49% OFF
ExpressVPN
A dependable VPN service that works on all devices and platforms.
A dependable VPN service that works on all devices and platforms. Show Less
TorGuard VPN
The best VPN service for torrenting safely and anonymously.
The best VPN service for torrenting safely and anonymously. Show Less
50% OFF
VuzeVPN
VuzeVPN offers you unlimited and unrestricted VPN service.
VuzeVPN offers you unlimited and unrestricted VPN service. Show Less
VeePN
VeePN is a virtual private network (VPN) service that provides online privacy and security by encrypting internet...Show More
VeePN is a virtual private network (VPN) service that provides online privacy and security by encrypting internet traffic and hiding the user's IP address. Show Less
HideMe VPN
HideMe VPN is your ultimate online privacy solution, providing secure and anonymous browsing while protecting your data...Show More
HideMe VPN is your ultimate online privacy solution, providing secure and anonymous browsing while protecting your data from prying eyes, so you can browse the internet with confidence and freedom. Show Less
ZoogVPN
ZoogVPN is the complete and trusted all-in-one VPN service that protects your sensitive personal and financial...Show More
ZoogVPN is the complete and trusted all-in-one VPN service that protects your sensitive personal and financial information online. Show Less
HideMyName VPN
Protect your online privacy and anonymity with HideMyName VPN, a secure and affordable service that offers robust...Show More
Protect your online privacy and anonymity with HideMyName VPN, a secure and affordable service that offers robust encryption, multiple server locations, and a variety of privacy-enhancing features. Show Less
Witopia VPN
Witopia VPN lets you shield your privacy and unlock the world's internet with military-grade encryption and borderless...Show More
Witopia VPN lets you shield your privacy and unlock the world's internet with military-grade encryption and borderless access. Show Less
FastestVPN
FastestVPN offers budget-friendly, secure connections with unlimited data and a focus on fast speeds, ideal for...Show More
FastestVPN offers budget-friendly, secure connections with unlimited data and a focus on fast speeds, ideal for streaming and everyday browsing. Show Less
ExtremeVPN
ExtremeVPN is a VPN service that offers fast speeds, strong encryption, and a no-logs policy to keep your online...Show More
ExtremeVPN is a VPN service that offers fast speeds, strong encryption, and a no-logs policy to keep your online activity private. Show Less
iProVPN
iProVPN is a VPN service with a focus on security and affordability, offering basic features to secure your connection...Show More
iProVPN is a VPN service with a focus on security and affordability, offering basic features to secure your connection and unblock streaming content. Show Less
When you browse the internet, a proxy server intermediate on your behalf, the requests you send are first received by a proxy server before being sent to the webserver.
Typically, a proxy server would send your requests as it is, but with a rotary proxy server, you use random IP addresses for each web request. Rotating proxy service provides do offer different Geo proxies, so you can use a proxy server in various countries which will switch your location.
Nodemaven
NodeMaven is a premium proxy provider that delivers high-quality IPs, super sticky sessions, and unmatched customer...Show More
NodeMaven is a premium proxy provider that delivers high-quality IPs, super sticky sessions, and unmatched customer support. Show Less
IPRoyal
IPRoyal is a leading proxy provider offering reliable, high-speed proxies for various needs, including data scraping...Show More
IPRoyal is a leading proxy provider offering reliable, high-speed proxies for various needs, including data scraping, social media automation, and sneaker botting. Show Less
Mars Proxies
Mars Proxies is the go-to provider for sneaker coppers, offering unbanned IPs, blazing-fast speeds, and a massive pool...Show More
Mars Proxies is the go-to provider for sneaker coppers, offering unbanned IPs, blazing-fast speeds, and a massive pool of residential proxies. Show Less
NetNut
NetNut is the world's fastest residential proxy network, providing high-speed, reliable connections and a vast pool of...Show More
NetNut is the world's fastest residential proxy network, providing high-speed, reliable connections and a vast pool of IPs for seamless data scraping and automation. Show Less
Infatica
Infatica provides a robust proxy network with ethical sourcing, reliable performance, and a comprehensive suite of data...Show More
Infatica provides a robust proxy network with ethical sourcing, reliable performance, and a comprehensive suite of data collection tools. Show Less
Decodo (formerly Smartproxy)
Decodo (formerly Smartproxy) provides premium residential proxies for bypassing geo-restrictions, CAPTCHAs, and IP...Show More
Decodo (formerly Smartproxy) provides premium residential proxies for bypassing geo-restrictions, CAPTCHAs, and IP blocks with industry-leading success rates and flexible pricing options. Show Less
Oxylabs
Oxylabs proxies offer diverse, ethical, and reliable solutions for data scraping, web testing, and privacy needs.
Oxylabs proxies offer diverse, ethical, and reliable solutions for data scraping, web testing, and privacy needs. Show Less
Webshare
Webshare is a company that provides proxy servers that are used for data aggregation, analysis, and collection.
Webshare is a company that provides proxy servers that are used for data aggregation, analysis, and collection. Show Less
Live Proxies
Live Proxies is a proxy service that provides high-speed, reliable, and secure residential and datacenter proxy services...Show More
Live Proxies is a proxy service that provides high-speed, reliable, and secure residential and datacenter proxy services for web scraping, automation, and anonymity. Show Less
DigiProxy
DigiProxy offers proxy services, including residential, datacenter, and sneaker proxies, aimed at providing secure and...Show More
DigiProxy offers proxy services, including residential, datacenter, and sneaker proxies, aimed at providing secure and reliable internet access. Show Less
Oxylabs
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and...Show More
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and scalable data-gathering tools to stay ahead of the competition. Show Less
Webshare
Webshare delivers fast, affordable, and customizable proxy solutions designed to give businesses and developers seamless...Show More
Webshare delivers fast, affordable, and customizable proxy solutions designed to give businesses and developers seamless access to reliable data at scale. Show Less
Decodo (formerly Smartproxy)
Decodo (formerly Smartproxy) provides powerful, user-friendly proxy and web scraping solutions that make large-scale...Show More
Decodo (formerly Smartproxy) provides powerful, user-friendly proxy and web scraping solutions that make large-scale data access effortless, efficient, and cost-effective. Show Less
Oxylabs
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and...Show More
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and scalable data-gathering tools to stay ahead of the competition. Show Less
Webshare
Webshare delivers fast, affordable, and customizable proxy solutions designed to give businesses and developers seamless...Show More
Webshare delivers fast, affordable, and customizable proxy solutions designed to give businesses and developers seamless access to reliable data at scale. Show Less
Oxylabs
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and...Show More
Oxylabs is a leading proxy and web scraping solutions provider that empowers businesses with reliable, high-speed, and scalable data-gathering tools to stay ahead of the competition. Show Less
Webshare
Webshare YouTube proxies deliver fast, reliable, and secure connections that let you bypass restrictions and stream...Show More
Webshare YouTube proxies deliver fast, reliable, and secure connections that let you bypass restrictions and stream, scrape, or manage multiple YouTube accounts seamlessly without interruptions. Show Less
Decodo (formerly Smartproxy)
Decodo (formerly Smartproxy) YouTube proxies provide high-quality, secure, and geo-flexible access that ensures smooth...Show More
Decodo (formerly Smartproxy) YouTube proxies provide high-quality, secure, and geo-flexible access that ensures smooth streaming, scraping, and account management on YouTube without blocks or interruptions. Show Less
Oxylabs
Oxylabs is a premium proxy and web intelligence solutions provider with 175M+ IPs across 195 countries, offering...Show More
Oxylabs is a premium proxy and web intelligence solutions provider with 175M+ IPs across 195 countries, offering ready-to-use Scraper APIs that seamlessly extract structured public data while bypassing IP blocks and CAPTCHAs. Show Less
Decodo (formerly Smartproxy)
Decodo (formerly Smartproxy) is an AI-powered proxy service and web scraping solutions provider that enables seamless...Show More
Decodo (formerly Smartproxy) is an AI-powered proxy service and web scraping solutions provider that enables seamless, large-scale data extraction with smart, reliable, and cost-effective tools for businesses of any size. Show Less
Decodo (formerly Smartproxy)
Decodo (formerly Smartproxy) is a powerful proxy service provider with advanced APIs, including its Amazon Scraping API...Show More
Decodo (formerly Smartproxy) is a powerful proxy service provider with advanced APIs, including its Amazon Scraping API, which delivers effortless, real-time access to accurate Amazon data at scale with zero blocks and zero maintenance. Show Less
Smart DNS Services
Just like IP addresses, DNS (Domain Name Server) can give out your exact location to websites online. With SmartDNS services, your original IP address is not hidden or changed; your request is simply re-routed.
Hence, your request does not go directly from your region but is passed through a different region before getting to the webserver. The web server receives the request with your original IP address but will read a different location based on the route it followed.
The Ultimate List Of Geo-restricted Streaming Services: Frequently Asked Questions
What Are Geo-Restricted Streaming Services?
Geo-restricted streaming services are platforms like Netflix, Hulu, Disney+, BBC iPlayer, and Amazon Prime Video that limit access to specific content based on the user’s geographic location due to licensing or regional policies.
Why Do Streaming Services Impose Geo-Restrictions?
These restrictions are primarily due to licensing agreements with content creators, regional copyright laws, and market-specific distribution deals that dictate what content can be shown in different countries.
How Can I Access Geo-Restricted Content?
Users often rely on VPNs (Virtual Private Networks) to mask their location, proxy servers, or Smart DNS services to bypass these restrictions by routing their internet connection through an allowed region.
Is It Legal to Bypass Geo-Restrictions?
While using tools like VPNs to access geo-blocked content is generally not illegal, it may violate the terms of service of streaming platforms, potentially leading to account suspension.
What Are Some Popular Geo-Restricted Streaming Services?
Services like HBO Max, Hulu, BBC iPlayer, ESPN+, Peacock, and regional versions of Netflix are common examples of platforms with content variations or availability restrictions based on location.
What Should I Consider Before Using a VPN for Streaming?
Check for a VPN that offers fast speeds, servers in the desired regions, compatibility with the streaming platform, and a no-logs policy to ensure privacy and smooth streaming experiences.
Geo-restricted content refers to online media or services accessible only in certain regions due to licensing agreements, copyright laws, or regional policies. For example, a TV show available on Netflix in the US might not be accessible in other countries.
Which VPN is best for geo-restricted content?
Popular VPNs like ExpressVPN, NordVPN, and Surfshark are often considered the best for bypassing geo-restrictions. These services offer fast servers in multiple countries, strong encryption, and the ability to unblock platforms like Netflix, Hulu, or Disney+.
Does Netflix geoblock?
Yes, Netflix geo-blocks its content based on the user’s location. The available shows and movies vary by country due to licensing deals, so users in different regions can access different libraries.
How do I view geo-blocked content?
To view geo-blocked content, you can use a VPN (Virtual Private Network) to change your virtual location. A VPN reroutes your internet traffic through a server in the desired country, allowing you to access restricted content.
How do I unblock geo-restricted content?
You can unblock geo-restricted content by using a VPN, proxy service, or Smart DNS. These tools mask your actual location, tricking websites into thinking you’re accessing them from an allowed region.
Is PayPal geo-restricted?
Yes, PayPal has geo-restrictions for certain services and features. For example, some countries may not support PayPal transactions, or specific features like withdrawing to a bank account may be limited based on location.
Conclusion
Geo-restrictions and copyright laws should not stop you from enjoying your favorite TV shows, movies, and songs. No matter what region you reside in, you can unblock geo-restriction by using various methods, as listed above.
This post will show you essential Squid Game cybersecurity tips to learn.
Netflix’s Squid Game took the world by storm, captivating audiences with its brutal depiction of 456 debt-ridden individuals competing in deadly children’s games for a massive cash prize.
Beyond its gripping storyline, the series offers profound cybersecurity lessons that mirror today’s digital threats. Just as contestants face life-or-death challenges, your sensitive data battles against relentless cybercriminals daily.
The Squid Game’s rules mirror classic childhood games turned deadly. The perimeter drawn in sand represents a squid’s outline, with defenders patrolling the boundaries and attackers attempting to breach them while hopping on one leg. Once past the defenders, attackers can use both legs to reach the “squid head” and win—but one wrong move means elimination (or death, in the show’s context).
This high-stakes game serves as a perfect metaphor for cybersecurity:
Defenders = Your security systems and IT team
Attackers = Cybercriminals probing for weaknesses
Squid Perimeter = Your network’s digital boundaries
Cybersecurity Lessons From Squid Game
Lesson
Description
Real-World Application
Don’t Trust Easily (Red Light, Green Light)
The unsuspecting players are eliminated for trusting the deceptive doll’s instructions.
Be cautious of online interactions and information. Verify sources, avoid clicking suspicious links, and be wary of overly generous offers.
Information Asymmetry (Honeycomb Game)
Players with prior knowledge of the game (shapes) have a significant advantage.
Attackers often exploit vulnerabilities in software or human error. Stay updated on cybersecurity threats and best practices.
Strength in Numbers (Tug-of-War)
The stronger team (more members) wins, highlighting the importance of teamwork.
Utilize multi-factor authentication and implement security measures across your entire network (personal or business).
Physical vs. Digital Security (Glass Bridge Game)
The “tempered” glass bridge represents strong security, while the “normal” glass is a security weakness.
Implement strong passwords data encryption, and regularly update software to patch vulnerabilities.
Desperation Breeds Risk (Marbles Game)
Players take extreme risks due to desperation in the game.
Financial desperation can make people more susceptible to phishing scams or malware. Be cautious of online financial opportunities, especially those promising quick and easy returns.
Beware of Internal Threats (The Hostage Situation)
The game’s mastermind is revealed as one of the participants.
Insider threats can be just as dangerous as external threats. Implement access controls and be mindful of who has access to sensitive information.
Case Study: The Red Light, Green Light Phishing Lesson
In 2022, Google reported blocking 100 million phishing emails daily. Just like players who moved during “Red Light” were eliminated, employees who click malicious links often compromise entire networks. A 2023 IBM study found that 95% of cybersecurity breaches result from human error—proving why verification is crucial.
What Does The Squid Game TV Series Have In Common With Cybersecurity?
Modern organizations face attacks from multiple vectors—cloud, mobile, IoT devices—just as Squid Game contestants faced unexpected challenges. Here’s the cybersecurity parallel:
The Squid Perimeter = Your network’s firewall and endpoint security
Defenders = Your SOC (Security Operations Center) team and tools like SIEM systems
Attackers = Advanced Persistent Threats (APTs) or ransomware gangs
The show’s unpredictable VIPs mirror advanced persistent threats (APTs). 34% of breaches in 2023 involved novel attack vectors (Source: Mandiant M-Trends).
Incident Response Plan Checklist:
Conduct quarterly tabletop exercises
Maintain an updated contact list for crisis response
Store offline backups (3-2-1 rule: 3 copies, 2 media types, 1 offsite)
Subscribe to threat intelligence feeds (Recorded Future, etc.)
Season 2 Cybersecurity Lessons: The Return of Deception 🎭
1. Advanced Social Engineering (The Recruitments)
In Season 2, returning or new participants are subtly manipulated into joining the deadly games, often through promises or emotional appeals. Just like in real life, attackers exploit trust to gain entry into systems.
Real-World Application:
Train employees regularly to spot phishing emails, fake calls, and pretexting attempts.
Simulate attacks through controlled phishing campaigns (tools like KnowBe4 or PhishMe).
Verify unusual requests for sensitive information, even if they appear to come from leadership.
Example: An employee receives a convincing “urgent invoice” email from finance. Without verification, clicking it could unleash malware — just as a contestant trusting the recruiter faces elimination.
2. Multi-Layered Monitoring (The Underground Games)
The hidden games in Season 2 feature multiple surveillance points, catching every subtle move, ensuring that mistakes don’t go unnoticed. In cybersecurity, single-layer defenses aren’t enough; threats can bypass one system and exploit another.
Real-World Application:
Continuous network monitoring using SIEM tools like Splunk or LogRhythm.
Behavioral analytics to detect unusual user activity or privilege misuse.
Example: Just like a contestant is watched by cameras in blind spots, attackers may lurk in systems unnoticed without comprehensive monitoring. Multiple layers make detection faster and containment more effective.
Season 3 Cybersecurity Lessons: Insider Threats Amplified 🕵️♂️
1. Exploiting Familiarity (The Insider Advantage)
Returning players leverage their prior knowledge to exploit vulnerabilities in new contestants. Similarly, insiders in organizations — whether employees, contractors, or partners — have knowledge that external attackers do not.
Real-World Application:
Role-Based Access Control (RBAC): Only allow access necessary for a user’s role.
Audit trails & logging: Track every action to identify suspicious behavior.
Periodic access reviews: Revoke privileges that are no longer needed.
Example: A former employee retains access to shared folders and exfiltrates data. Proactive monitoring and strict access controls prevent such exploitation.
2. Contingency Planning (The Extreme Twists)
Season 3 throws unexpected twists at players — sudden rule changes, hidden traps, and ambushes. Cybersecurity faces similar uncertainty with zero-day exploits, ransomware, and advanced persistent threats (APTs).
Real-World Application:
Incident response plan: Keep it updated, test it quarterly, and include clear communication protocols.
Redundant backups: Apply the 3-2-1 rule (3 copies, 2 media types, 1 offsite).
Rapid patch management: Ensure critical updates are applied within hours of release.
Example: A ransomware attack encrypts critical servers. Organizations with tested contingency plans restore systems quickly, just as contestants adapt to survive sudden game changes.
✅ Key Takeaways From Seasons 2 & 3:
Trust is currency: Never assume trust — verify everything (Zero Trust).
Knowledge is power: Insider awareness and monitoring prevent exploitation.
Layer your defenses: One line of defense is never enough.
Plan for surprises: Cyberattacks evolve; preparation reduces damage.
Squid Game Cybersecurity Lessons Table: Seasons 1–3
Lesson
Season & Game
Description
Real-World Application / Actionable Tip
Don’t Trust Easily
S1 – Red Light, Green Light
Players eliminated for trusting deceptive instructions.
Avoid hasty financial or security decisions. Train staff to recognize scams, phishing, and malware.
Beware of Internal Threats
S1 – Hostage Situation
Game mastermind is one of the participants.
Implement RBAC, audit logs, insider threat monitoring, and access reviews.
Advanced Social Engineering
S2 – Recruitments
Returning or new participants manipulated psychologically.
Conduct phishing simulations, train staff on social engineering, verify all unusual requests.
Multi-Layered Monitoring
S2 – Underground Games
Multiple surveillance systems catch mistakes.
Deploy SIEM, EDR, and behavioral analytics for continuous monitoring. Redundant checks prevent undetected breaches.
Exploiting Familiarity
S3 – Insider Advantage
Returning players exploit knowledge to gain edge.
Limit insider risk through RBAC, privilege reviews, logging, and monitoring suspicious behavior.
Contingency Planning
S3 – Extreme Twists
Unexpected twists force rapid adaptation.
Maintain and test incident response plans, use 3-2-1 backups, and implement rapid patching for zero-day threats.
✅ How to Read This Table
Season & Game: Identifies the Squid Game season and specific in-show game that illustrates the lesson.
Lesson: The cybersecurity principle inspired by the show.
Description: Explains the in-show analogy for easier understanding.
Real-World Application: Concrete, actionable cybersecurity steps you can implement immediately.
Cybersecurity Lessons From Squid Game: FAQs
The show highlights distrust as a key cybersecurity principle. Isn’t that a bit extreme?
While absolute distrust isn’t practical, zero-trust architecture is now industry standard. Google’s BeyondCorp model proves that verifying every access request reduces breaches by 50%+.
How can small businesses implement Squid Game-level security affordably?
Start with these low-cost measures:
Enable free MFA (Microsoft Authenticator, Google Authenticator)
Use built-in security tools (Windows Defender, macOS Gatekeeper)
Train staff with phishing simulation tools (KnowBe4 has free tiers)
How does the “information asymmetry” in the Honeycomb Game apply to real-world cybersecurity?
Just like players with shape knowledge had an advantage, cybercriminals exploit unpatched vulnerabilities. The CISA KEV Catalog shows 60% of breaches use vulnerabilities where patches existed but weren’t applied. Always update systems within 72 hours of patch releases.
The Marbles Game shows desperation leading to bad decisions. How does this translate to cyber risks?
Financial stress makes people 3x more likely to fall for “get rich quick” scams (FBI Internet Crime Report 2023). During economic downturns, fake investment scams increase by 200%. Always verify opportunities through official channels before acting.
What’s the cybersecurity equivalent of the Glass Bridge’s “testing each step”?
This mirrors penetration testing:
Conduct annual red team exercises
Use automated vulnerability scanners weekly
Test backup restoration quarterly (40% of backups fail when needed)
How can teams collaborate securely like the Tug-of-War game winners?
Implement team-based security:
Shared password managers (Bitwarden, 1Password)
Role-based access controls (RBAC)
Security champion programs in each department
Microsoft found this approach reduces incidents by 58%.
The show features disguised threats. What’s the cybersecurity parallel?
This represents fileless malware and living-off-the-land attacks:
31% of attacks now use legitimate tools like PowerShell
How does the “elimination” concept apply to cybersecurity?
This mirrors automated threat containment:
Set SIEM rules to isolate compromised devices
Automatically revoke credentials after 3 failed logins
Quarantine suspicious emails with sandboxing
Gartner shows this reduces breach impact by 72%.
Conclusion – Squid Game Cybersecurity Tips
Just as Squid Game contestants faced escalating challenges, cyber threats grow more sophisticated yearly. A 2023 CyberArk study found attacks increased by 38% YoY. By implementing these layered defenses—network segmentation, EDR, employee training—you create a security posture as resilient as the show’s tempered glass.