


How to Train a GPT Model (Step-by-Step): Methods, Tools & Real-World Guide
Artificial Intelligence has changed how humans interact with technology. From chatbots and AI writing assistants to recommendation engines, GPT (Generative Pre-trained Transformer) models power much of today’s AI revolution.
But behind every smart AI that writes, codes, or talks naturally lies a process — training.
If you’ve ever wondered how GPT models learn to generate human-like text, this guide walks you through every stage of the journey — from preparing datasets to deploying your fine-tuned model live.
Table of Contents
⚙️ What Does “Training a GPT Model” Mean?
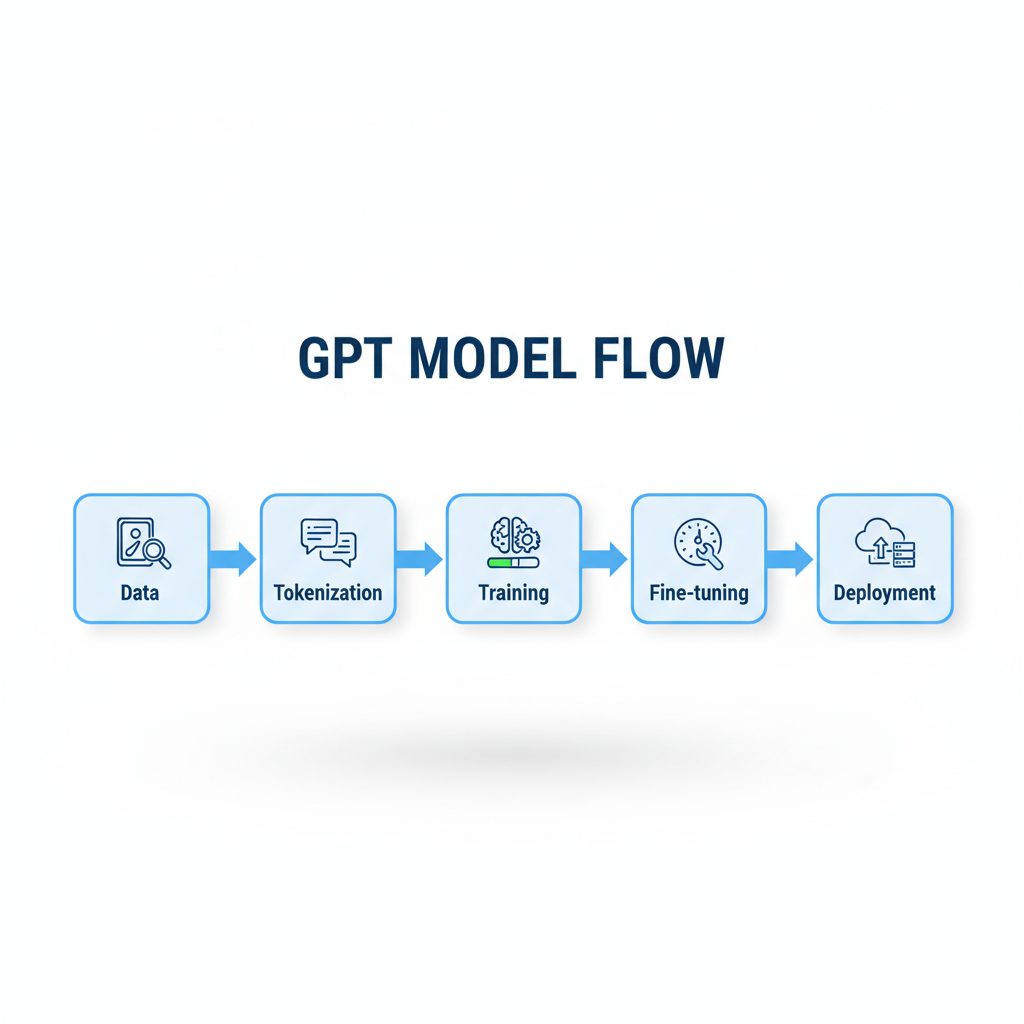
Training a GPT model means teaching an algorithm to understand and predict human language.
At the core, a Transformer architecture processes text sequences and learns relationships between words and concepts.
When training:
- You feed the model massive amounts of text data.
- It learns context, semantics, and patterns.
- The output becomes a model that can generate or complete text just like a human.
There are two main ways to train a GPT model:
- Pre-training – Building a model from scratch.
- Fine-tuning – Adapting an existing model for a specific task or domain.
🧩 Step 1: Choose Your Training Objective
Before jumping into code or GPUs, clarify why you’re training the model.
Common goals include:
- 🗣️ Conversational AI – Chatbots, assistants, or customer support.
- 📝 Content Generation – Blogs, marketing copy, storytelling.
- 🧮 Code Generation – Python, JavaScript, SQL automation.
- 🔍 Information Retrieval – Summarization or document Q&A.
- 💬 Sentiment Analysis – Detecting tone or emotion in text.
Your objective defines your dataset, architecture size, and training method.
🧱 Step 2: Pick the Right Model Base
You don’t always need to start from zero.
Choose between:
| Approach | Description | Example Models |
|---|---|---|
| From Scratch | Train a new model with raw text data. Requires huge compute power. | GPT-Neo, GPT-J |
| Fine-tuning | Use a pre-trained GPT (like GPT-2, GPT-3, or LLaMA) and adapt it to your dataset. | GPT-3 Fine-tuned, GPT-NeoX |
| Instruction Tuning | Adjusts GPTs to follow commands better using curated prompts. | Alpaca, Vicuna |
💡 Pro Tip: Most developers today choose fine-tuning for efficiency and cost.
💾 Step 3: Gather and Clean Your Dataset
🔍 What Makes a Good Dataset?
Your dataset determines your model’s quality. A high-performing GPT requires:
- Diverse and domain-relevant data
- Balanced tone and grammar
- Ethical, non-toxic language
Common Dataset Sources:
- OpenAI Datasets
- The Pile
- Common Crawl
- Wikipedia Dumps
- Reddit or StackOverflow Scrapes (filtered)
You can also create custom datasets for:
- Customer support logs
- Legal or medical text
- Marketing or product descriptions
🧹 Data Cleaning Checklist:
- Remove duplicates and profanity
- Normalize punctuation and casing
- Tokenize text correctly
- Ensure encoding (UTF-8) consistency
A single error in formatting can break training, so validate data structure before running your script.

🧮 Step 4: Tokenization — The Secret Language of GPTs
Tokenization converts text into numerical units the model can understand.
Example:
“Train GPT models effectively” →
[502, 7711, 203, 9883]
Popular tokenizers:
- Byte-Pair Encoding (BPE) – used in GPT-2/GPT-3
- SentencePiece – for multilingual tasks
- Tiktoken (by OpenAI) – optimized for GPT APIs
💡 Pro Tip: Use the same tokenizer as your base model. Mismatch = chaos.
⚡ Step 5: Select Your Training Framework
Here’s what most professionals use:
| Framework | Description | Best For |
|---|---|---|
| PyTorch | Widely used deep learning framework. | Research and flexible fine-tuning |
| TensorFlow | Google’s deep learning library. | Scalable, production-level training |
| Hugging Face Transformers | Simplifies GPT training. | Fast prototyping and customization |
| DeepSpeed / Megatron-LM | Optimized for large model training. | Enterprise-grade GPTs |
💻 Step 6: Infrastructure and Compute Power
GPT training is GPU-heavy.
Here’s what you need depending on model scale (estimate):
| Model Type | GPU Requirement | Approx. Cost |
|---|---|---|
| Small (GPT-2) | 1 GPU (e.g., RTX 3090) | $200–$500 |
| Medium (GPT-J) | 4–8 GPUs | $2,000+ |
| Large (GPT-3 style) | 16–32 GPUs or TPU pods | $20,000+ |
For individuals or startups, cloud platforms are ideal.
🚀 Recommended Cloud Providers:
- AWS EC2 (with Deep Learning AMIs)
- Google Cloud TPU Pods
- Paperspace / Lambda Labs
Recommended Best Proxy Service for GPT: Decodo

💎 Tip: GPU clusters allow on-demand scaling and prebuilt GPT fine-tuning templates — perfect for researchers and small teams.
🛡️ Why Proxies Matter in GPT Training — and Why Decodo Is the Best Choice
Training or fine-tuning a GPT model doesn’t happen in isolation — you rely on multiple data sources, APIs, documentation endpoints, model checkpoints, and package registries. All of these external connections make your training pipeline vulnerable to rate limits, IP bans, throttling, and DNS-level restrictions.
This is exactly why proxies matter when building or training GPT models, especially at scale.
Why Do You Need Proxies for GPT Training & Dataset Collection?
1. Web Scraping for Training Data Requires Stability
Many AI teams scrape websites for high-quality domain-specific text.
Without proxies:
- Your IP gets blocked after several requests
- Data collection halts midway
- Inconsistent datasets break your training batches
Using rotating residential proxies ensures uninterrupted scraping sessions.
2. API Endpoints Often Enforce Region Locks
Some model hubs, dataset repositories, and code sources throttle or region-limit access.
Proxies solve this by giving you:
- Access to global endpoints
- Stable regional routing
- Zero downtime during long-running training jobs
3. Distributed GPU Clusters Need Secure External Connections
When training models across:
- AWS
- Google Cloud
- Paperspace
- Lambda Labs
…different nodes often hit rate limits when downloading model weights or connecting to services simultaneously.
A proxy layer evens out the traffic flow and reduces interruptions.
Why Decodo Proxies Are Ideal for GPT Model Training Workflows
If your AI pipeline touches the internet — which it always does — Decodo is one of the most reliable choices.
Here’s why:
✔ High-Quality Residential IPs
Perfect for scraping datasets, documentation sites, tutorial pages, and public knowledge sources without getting flagged.
✔ Rotating and Static Options
You choose whether your training node needs a stable IP or an automatic rotation every request.
✔ Fast and Stable — Critical for Downloading Large Model Files
GPT weights are huge. Slow proxies = broken downloads.
Decodo ensures consistent throughput.
✔ Affordable for Continuous AI Research
Training GPTs is expensive — Decodo keeps data access affordable.
✔ Developer-Friendly Setup
Easy integration with:
- Python
- Scrapy
- Playwright
- Hugging Face
- FastAPI
✔ Perfect for Scaling
Whether you’re training on:
- A single RTX 3090
- A multi-node A100 cluster
- TPU pods
…Decodo’s rotating network distributes the load evenly.
🔧 Example: Using Decodo Proxies in a Python GPT Training Pipeline
This simple addition protects your dataset gathering, prevents interruptions, and guarantees continuous data ingestion for your GPT model.
📦 Recommended: Decodo Proxy Plans for AI Developers
If you’re running:
- Small-scale fine-tuning: Choose rotating residential proxies.
- Large-scale data scraping for AI corpora: Choose residential proxy pools with large IP diversity.
- Enterprise-level GPT training: Static dedicated residential IPs.
🔬 Step 7: Fine-Tuning the Model
Here’s a simplified Hugging Face-based fine-tuning flow:
✅ Use Hostinger Cloud’s pre-optimized GPT runtime for faster convergence (up to 3x faster on A100s).
📊 Step 8: Evaluate and Optimize
Evaluate using metrics like:
- Perplexity – how well the model predicts the next word
- BLEU/ROUGE – text similarity scores
- Human Evaluation – check fluency and coherence
If accuracy lags, adjust:
- Learning rate
- Batch size
- Dataset quality
- Epoch count
💡 Pro Tip: Fine-tuning small batches over multiple epochs often beats one long run.
☁️ Step 9: Deployment and API Integration

After training, deploy your model for real-world use.
Options:
- Deploy via Hugging Face Hub
- Use Flask/FastAPI for REST endpoints
- Integrate with the API hosting layer
Example with FastAPI:
from fastapi import FastAPI
from transformers import pipelinegenerator = pipeline(“text-generation”, model=“./my_gpt_model”))
def generate(prompt: str):
return generator(prompt, max_length=100)
🔐 Step 10: Ethics, Compliance & Scaling
AI power demands responsibility.
Always ensure:
- No hate speech or bias in dataset
- Transparency about AI usage
- Compliance with data privacy laws (GDPR, CCPA)
Scaling comes after ethical foundation. Use Model Monitor to automatically flag unethical or biased outputs in real time.
🧭 The Future of GPT Training
GPT-5, GPT-Next, and beyond will likely:
- Integrate multi-modal data (images + audio + text)
- Use reinforcement learning from human feedback (RLHF)
- Run on distributed GPU swarms for democratized AI training
The future of AI isn’t locked in labs — it’s open, decentralized, and guided by creators like you.
🎯 Conclusion
Training a GPT model is no longer the exclusive domain of billion-dollar labs. With the right tools, mindset, and cloud infrastructure, you can build a model tailored to your mission.
Whether you’re building a writing assistant, teaching a chatbot empathy, or exploring AI research — the steps you’ve learned here will serve as your foundation.
And when you’re ready to scale, use GPU Hosting providers as your AI ally — powering everything from model training to cloud deployment with simplicity and speed.
Training GPT models requires:
- Clean, high-quality data
- Stable internet access
- Unrestricted API endpoints
- Fast downloads of large model files
- Protected network identity
Without proxies, you invite rate limits, IP bans, and broken pipelines.
Decodo solves all of that — giving you a seamless, scalable foundation for any GPT training workflow, from small projects to enterprise-level AI research.
✅ Quick Summary Table
| Stage | Description | Tools |
|---|---|---|
| 1. Objective | Define task | NLP Goal Setup |
| 2. Model | Pick base GPT | GPT-2 / GPT-J |
| 3. Dataset | Collect & clean | Common Crawl |
| 4. Tokenize | Encode text | BPE / SentencePiece |
| 5. Framework | Choose platform | PyTorch, HF |
| 6. Compute | GPUs & cloud | AWS |
| 7. Train | Fine-tune model | Trainer API |
| 8. Evaluate | Test accuracy | Perplexity, BLEU |
| 9. Deploy | API integration | FastAPI |
| 10. Scale | Ethics + speed | AI Monitor |
Leave us a comment below
INTERESTING POSTS
- Cybersecurity Maturity Report Released: Why Detecting Cyber Attacks Is Not Enough
- Exploring Model Monitoring Tools and Platforms for Effective Deployment
- AI in Breach Detection Threat or Safeguard (or Both)
- 6 Strategies To Make Your Model Serving API More Robust With Testing & Analysis
- Optimizing Your Event Log Management with a Maturity Model
- How to Set Up an MCP Server (2025 Guide)
- Residential vs Datacenter Proxies — Which Should You Choose?
- What Are Rotating Proxies? Types, Benefits & Use Cases (2025 Guide)
- Proxy for Scraping Amazon: The Ultimate Guide (2025 Edition)
About the Author:
Meet Angela Daniel, an esteemed cybersecurity expert and the Associate Editor at SecureBlitz. With a profound understanding of the digital security landscape, Angela is dedicated to sharing her wealth of knowledge with readers. Her insightful articles delve into the intricacies of cybersecurity, offering a beacon of understanding in the ever-evolving realm of online safety.
Angela's expertise is grounded in a passion for staying at the forefront of emerging threats and protective measures. Her commitment to empowering individuals and organizations with the tools and insights to safeguard their digital presence is unwavering.



{kind=link}